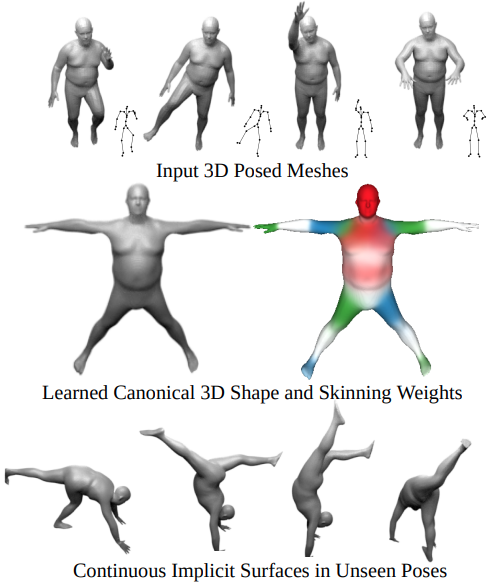
StyleGAN - Introduction Input latent space 가 train data 의 probability 를 따르다보면, entanglement 발생 StyleGAN 에선 intermediate latent space 를 사용함으로서 disentangle 시킬 수 있음 Perceptual path length 와 Linear seperability 를 제안 - Method 기존 PGGAN 에서 z 를 input 으로 주던 것과 달리, StyleGAN 에선 Constant 로 부터 시작함 z 는 non-linear mapping network f 를 통해 w 로 mapping Mapping network f 는 8 layer MLP 로 512 dimension 을 갖도록 구성 w 를 $..