- Introduction

최근 monocular video 에서 NeRF 를 이용한 avatar reconstruction 등장
NeRF 는 canonical space 를 사용하는 model (canonical space 라는 단어가 굉장히 많이 등장)
Canonical space 란?
- canonical: 기본형의, 표준이 되는
- Canonical space: Object-centered coordinate system
- View space: Viewer-centered coordinate system
좋은 성능을 내지만 (1) Differentiable deformation module 과 (2) Volume rendering 두 가지에 의해 다음과 같은 문제점 발생
- 오랜 train 시간
- 실시간 rendering 불가
► InstantAvatar
- Instant-NGP 를 사용하여 빠른 neural volume rendering - Limited to rigid objects (Rigid object: 강체, 힘을 가해도 변하지 않는 부분)
- Fast-SNARF 를 도입하여 continuous deformation field 로 하여금 효과적으로 canonical radiance field 를 posed space 로 warp
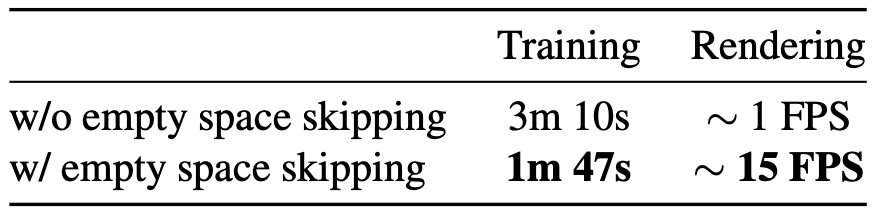
- Computational bottleneck 으로 인해 위 두 가지를 사용하더라도 완벽한 acceleration 은 힘들기 때문에 dynamic scene 에서 활용 가능한 Empty space skipping scheme 을 제안
- Inference time: Regular grid 에서 point sampling 을 하여 canonical model 로 보내어 density query → Yield occupancy grid (Occupancy grid: 점유 그리드, 물체가 있는 공간으로 나머지는 free space)
- Train time: Shared occupancy grid 를 가지고 있어 프레임끼리의 union 계산하고 몇 iter 마다 update
- Related Work
3D Human Reconstruction
- High-quality reconstruction
- Leverage personalized or generic templates (i.e. SMPL)
- Neural representations → Slow training and rendering speed
Accelerating Neural Radiance Field
- Use voxel grids for fast training and inference (i.e. instant-NGP) → Only for rigid objects
- Method
Efficient Canonical Neural Radiance Field
$\begin{aligned} \mathbf{f}_{\sigma_f}: \mathbb{R}^3 & \rightarrow \mathbb{R}^{+}, \mathbb{R}^3 \\ \mathbf{x} & \mapsto \sigma, c\end{aligned}$
Parameterized by Instant-NGP
Articulation Radiance Fields
To create animations and learn from the posed image
$\begin{aligned} \mathbf{f}_{\sigma_f}^{\prime}: \mathbb{R}^3 & \rightarrow \mathbb{R}^{+}, \mathbb{R}^3 \\ \mathbf{x}^{\prime} & \mapsto \sigma, c,\end{aligned}$
Skinning weight field to map canonical space to model articulation
$\begin{aligned} \mathbf{w}_{\sigma_w}: \mathbb{R}^3 & \rightarrow \mathbb{R}^{n_b} \\ \mathbf{x} & \mapsto w_1, \ldots, w_{n_b}\end{aligned}$
Computational cost 를 낮추기 위해 Fast-SNARF 를 통해 skinning weight field 를 low-resolution voxel grid 로 represent
각 grid point 는 SMPL model 에서 가장 가까운 vertex 의 skinning weight 로 판단
Target bone transformations $\mathbf{B}=\left\{\mathbf{B}_1, \ldots, \mathbf{B}_{n_b}\right\}$
Linear blend skinning $\mathbf{x}^{\prime}=\sum_{i=1}^{n_b} w_i \mathbf{B}_i \mathbf{x}$
Deformed point $\mathbf{x}^{\prime}$ 의 canonical correspondence $\mathbf{x}^*$ 는 Linear blend skinning 의 역함수로 나타남 → Fast-SNARF 의 root-finding 으로 부터 나옴 $\mathbf{f}_{\sigma_f}^{\prime}\left(\mathbf{x}^{\prime}\right)=\mathbf{f}_{\sigma_f}\left(\mathbf{x}^*\right)$

Rendering Radiance Fields
Ray $\mathbf{r}=\mathbf{o}+t \mathbf{d}$ 한 개를 선정
그 중에서 point $N$ 개를 sample $\left\{\mathbf{x}_i^{\prime}\right\}^N$ 한 이후 articulated radiance field $\mathbf{f}_{\sigma_f}^{\prime}$ 로 부터 color 와 density 를 query
$C=\sum_{i=1}^N \alpha_i \prod_{j<i}\left(1-\alpha_j\right) c_i$, with $\alpha_i=1-\exp \left(\sigma_i \delta_i\right)$ $\delta_i=\left\|\mathbf{x}_{i+1}^{\prime}-\mathbf{x}_i^{\prime}\right\|$
여기에서, acceleration module 의 경우 이미 기존 NeRF 나 SNARF 와 같은 naive method 와 비교했을 때 충분히 빨라졌지만 rendering 자체로 bottelneck 발생
Empty Space Skipping for Dynamic Objects
사람에게 3D bounding box 를 치면 남는 공간이 많기 때문에, 이 공간을 모두 rendering 하는 경우 오랜 시간이 걸림
Rigid object 의 경우엔 occupancy grid 를 이용하여 필요 없는 부분은 건너뛰면 되지만 Dynamic object 의 경우 pose 에 따라 frame 마다 다름
Inference Stage
$64 \times 64 \times 64$ 사이즈의 grid 를 이용하여 threshold 를 기준으로 density 를 binary 로 정함
빈 공간으로 잘못 예측 되는 경우를 방지하기 위해 occupancy region 을 팽창
occupancy grid 를 construct 하는데 것은 거의 무시해도 될 정도의 overhead (비용)
Train Stage
Train time 엔 occupancy grid 를 construct 하는 것을 무시할 수 없음
따라서 각 frame 에 나오는 occupancy region 의 union 으로 단 하나의 occupancy grid 사용하고 $k$ iteration 마다 update
여기에서 나오는 occupancy grid 는 nomalized space 에서 정의되기 때문에, union 이 tight 하게 생성됨
Training Losses
$\mathcal{L}_{\mathrm{rgb}}=\rho\left(\left\|C-C_{g t}\right\|\right)$
$\mathcal{L}_{\text {alpha }}=\left\|\alpha-\alpha_{g t}\right\|_1$
Hard Surface Regularization
LOLNeRF 에서 가지고옴
$\mathcal{L}_{\text {hard }}=-\log \left(\exp ^{-|\alpha|}+\exp ^{-|\alpha-1|}\right)+$ const
Occupancy-based regularization
SMPL 대신 Occupancy grid 를 이용한 Loss
$\mathcal{L}_{\text {density }}= \begin{cases}|\sigma(\mathbf{x})| & \text { if } \mathbf{x} \text { is in the empty space } \\ 0 & \text { otherwise }\end{cases}$
- Experiment
Datasets
- PeopleSnapshot: From Anim-NeRF
- SURREAL: PeopleSnapshot 을 SMPL 을 통해 OOD pose 생성
Baseline
- Anim-NeRF
- Neural Body

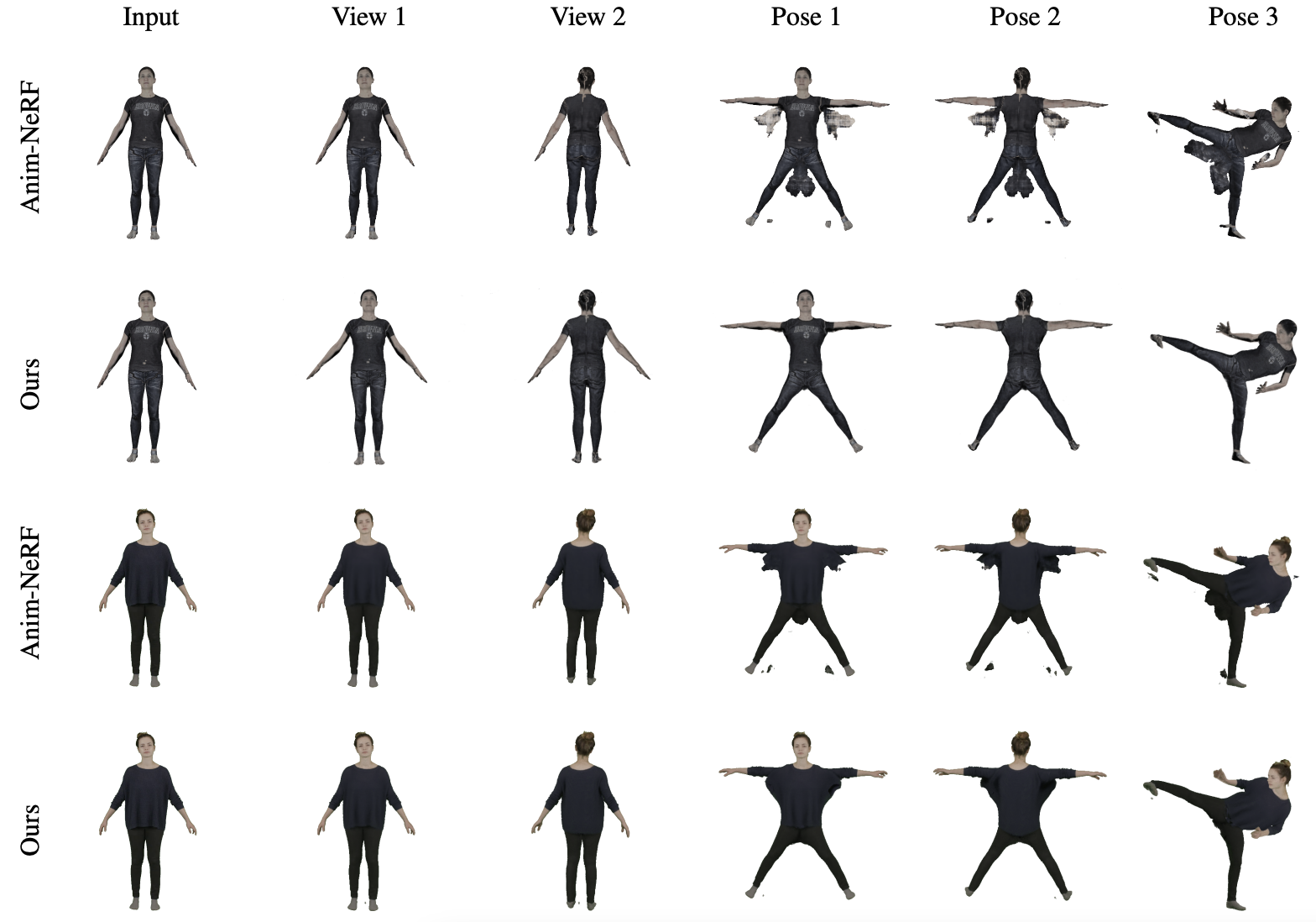


- Discussion
영상에서 안나오는 부분 unseen 에 대한 reconstruction 이 되지 않음
- Reference
[1] Jiang, Tianjian, et al. "Instantavatar: Learning avatars from monocular video in 60 seconds." CVPR 2023 [Paper link]