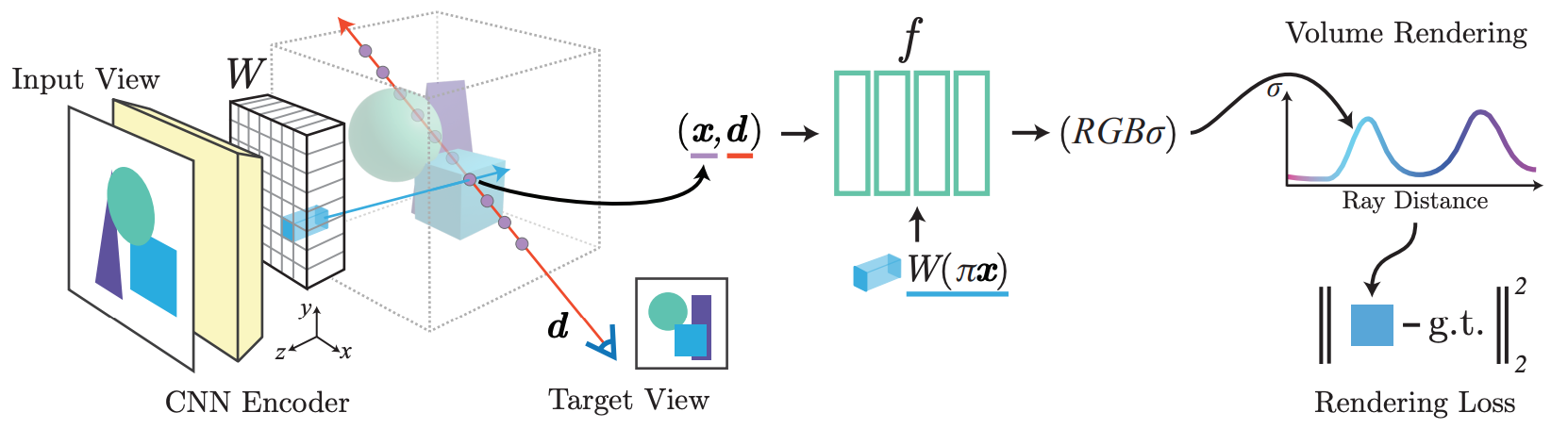
DUST3R 연구 흐름은 아래 링크 참고 바랍니다. GitHub - Ethan-Lee-Sunghoon/Awesome-DUST3R: A curated list of awesome DUST3R/MAST3R related papers.A curated list of awesome DUST3R/MAST3R related papers. - Ethan-Lee-Sunghoon/Awesome-DUST3Rgithub.com - Introduction현대 3D reconstruction 은 아래의 하위 분야들을 통합한 결과라고 볼 수 있음1. Keypoint detection (키포인트 감지)- 이미지에서 특징이 될 만한 중요한 점들을 찾아내는 과정- 예: 모서리, 코너, 특이한 텍스처가 있는 부분 등- 대표적인 알고리즘..