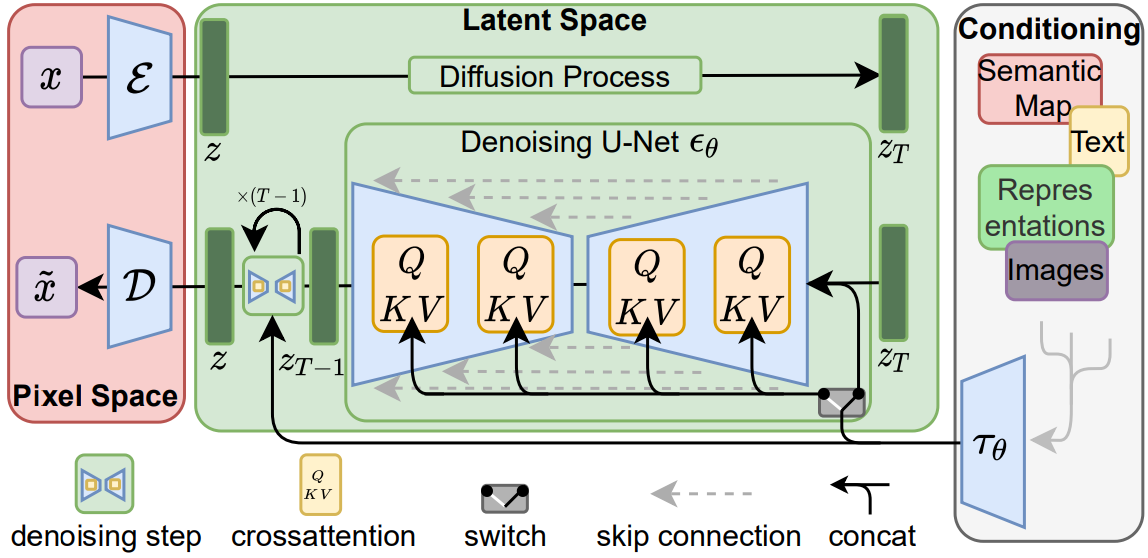
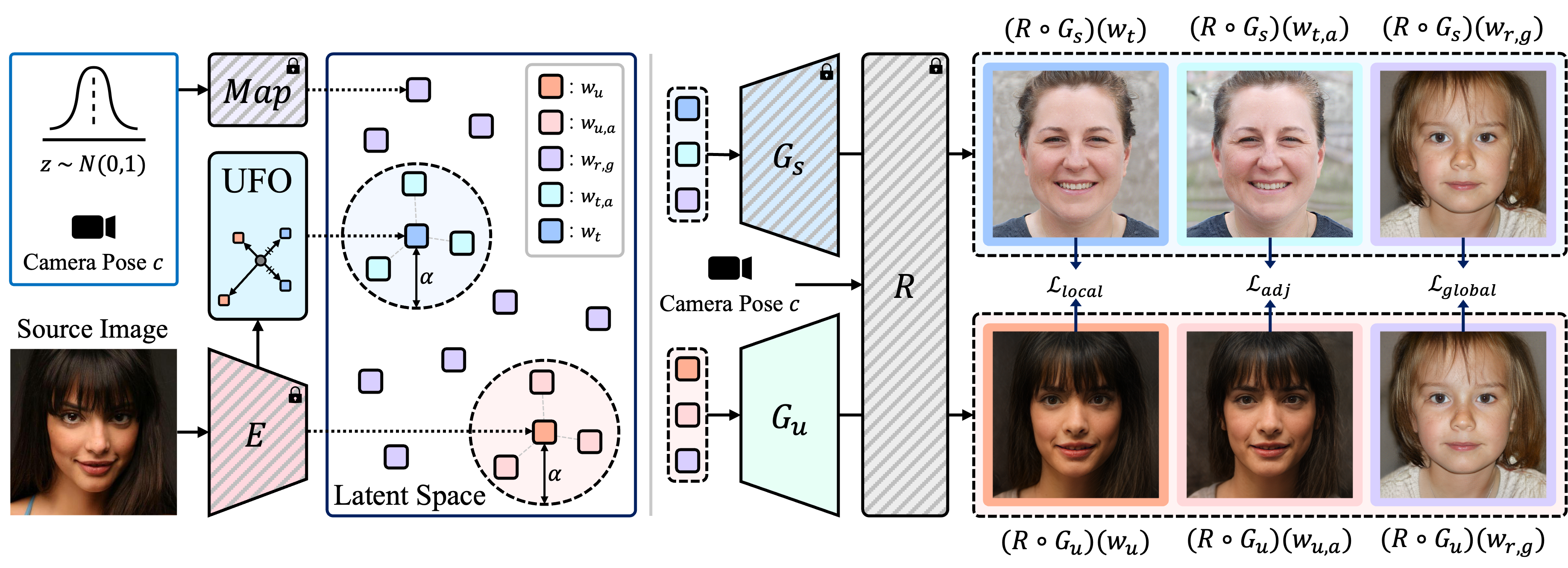
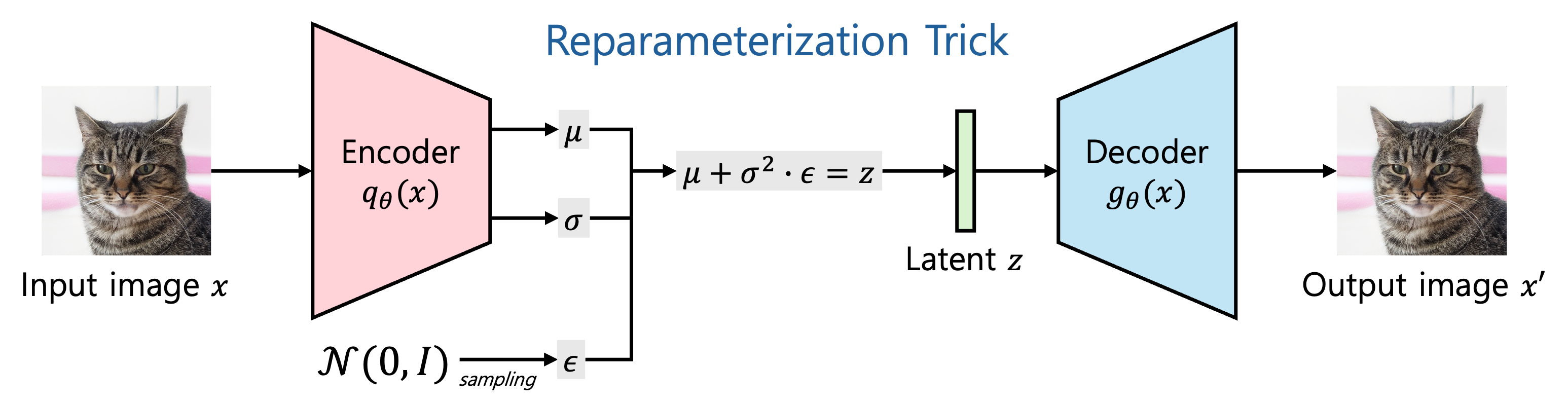
Stable Diffusion (SD) code 를 다른 opensource 와 마찬가지로 공식 github 에서 받아 돌려봤는데, 돌리긴 어렵진 않은데 ChatGPT 에 있는 Dall-E 와 비교했을 때 사용법이 좀 불편하다는 것을 느낌 일단 LDM 공식 github 실험 결과를 보자. Weight 는 Huggingface [2] 에서 SD v1-5 를 사용했고 GPU 는 연구실에서 사용하던 Ubuntu 서버로 따로 학습은 진행하지 않고 Sampling 만 진행 Img2Img 이 실험은 내 증명사진으로 진행을 해봤음 제일 왼쪽 사진이 내 증명사진이고 오른쪽 10장의 이미지는 정확한 prompt 는 기억이 나지 않지만... '얼굴을 좀 더 잘생기게 바꿔줘' 이런 내용이 들어갔던것 같은데.. 성능이 좀 별..