- Introduction
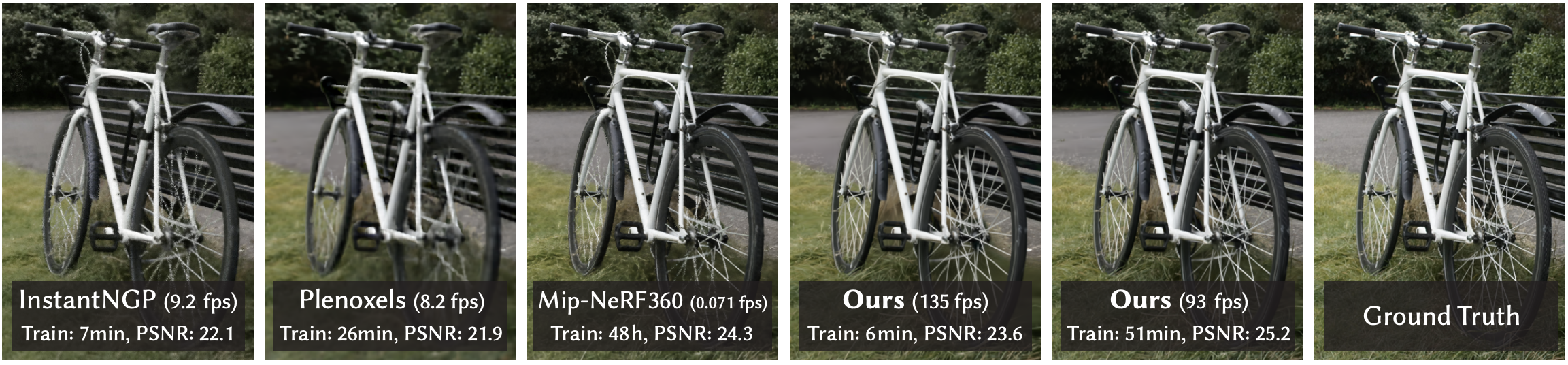
Gaussian Splatting 은 기존에 품질이 3D recon 분야에서 제일 좋다고 평가되던 Mip-NeRF (CVPR 2022) 보다 더 좋은 품질과 학습이 빠르기로 유명한 Instant-NGP (SIGGRAPH 2022) 보다 더 빠른 학습으로 최근 굉장히 각광 받고 있음
Goal of this paper: Real-time high-resolution rendering
Main components of Gaussian Splatting
- NeRF 와 똑같이 SfM (Structure-from-Motion) point 를 input 으로 받음 ↔︎ MVS (Multi-View Stereo) data 를 요구하는 point-based method 들과는 다름
- Optimization of 3D Gaussians
- Tile-based rasterization
SfM (Structure-from-Motion) & MVS (Multi-View Stereo)
SfM (Structure-from-Motion)
정의: 2D 이미지들로부터 3D 구조를 복원하는 컴퓨터 비전 기술
기본 원리:
- 서로 다른 각도에서 촬영된 여러 장의 2D 이미지를 입력으로 사용
- 각 이미지에서 특징점(feature points)을 추출
- 이미지들 간의 특징점 매칭을 통해 대응점을 찾기
- 카메라의 움직임(motion)과 3D 공간상의 점들(structure)을 동시에 추정
MVS (Multi-View Stereo)
정의: 캘리브레이션된 여러 장의 이미지로부터 3차원 기하 정보를 복원하는 컴퓨터 비전 기술
SfM 의 결과물인 카메라 파라미터를 입력으로 받아, 더 조밀하고 정확한 3D 모델을 생성하는 것이 목적
기본 원리:
- 포토메트릭 일관성 (Photometric Consistency)
- 동일한 3D 점이 여러 이미지에서 관찰될 때 유사한 외관을 가져야 한다는 원리
- 색상 값이나 특징점의 유사도를 측정하여 일치성 평가
- NCC(Normalized Cross Correlation)나 Sum of Squared Differences(SSD) 등의 메트릭 사용
- 깊이 맵 추정 (Depth Map Estimation)
- 각 참조 이미지의 픽셀마다 깊이 값을 추정
- 여러 깊이 가설에 대해 주변 이미지들과의 일치도 계산
- 가장 높은 일치도를 보이는 깊이를 선택
- 기하학적 제약 (Geometric Constraints)
- 에피폴라 기하학 활용
- 표면 법선 방향 고려
- 깊이의 연속성과 부드러움 가정
- 시점 선택 (View Selection)
- 각 참조 뷰에 대해 가장 정보가 유용한 주변 뷰들을 선택
- 베이스라인과 시야각을 고려
- 가시성 검사를 통한 폐색 영역 처리
- 깊이 맵 융합 (Depth Map Fusion)
- 여러 시점에서 추정된 깊이 맵들을 하나의 일관된 3D 모델로 통합
- 중복되는 측정값들의 통계적 처리
- 이상치 제거 및 노이즈 필터링
Main Contribution
- Anisotropic (이방성) 3D Gaussians 을 통한 고품질, unstructured representation
- 3D Gaussian property 들을 위한 optimization methods, adaptive density control
- Fast, differentiable rendering approach for GPU, anisotropic splatting and fast back prop
- Related Works
1. Traditional Scene Reconstruction and Rendering
1-1 Light Field
처음 나온 novel-view synthesis 기법들은 light fields 를 기반으로 하였음
Light field 방식은 실제 세계의 빛의 흐름을 포착하여 이미지 생성
* Light field 가 뭔지 잘 몰라서 좀 더 알아봤음
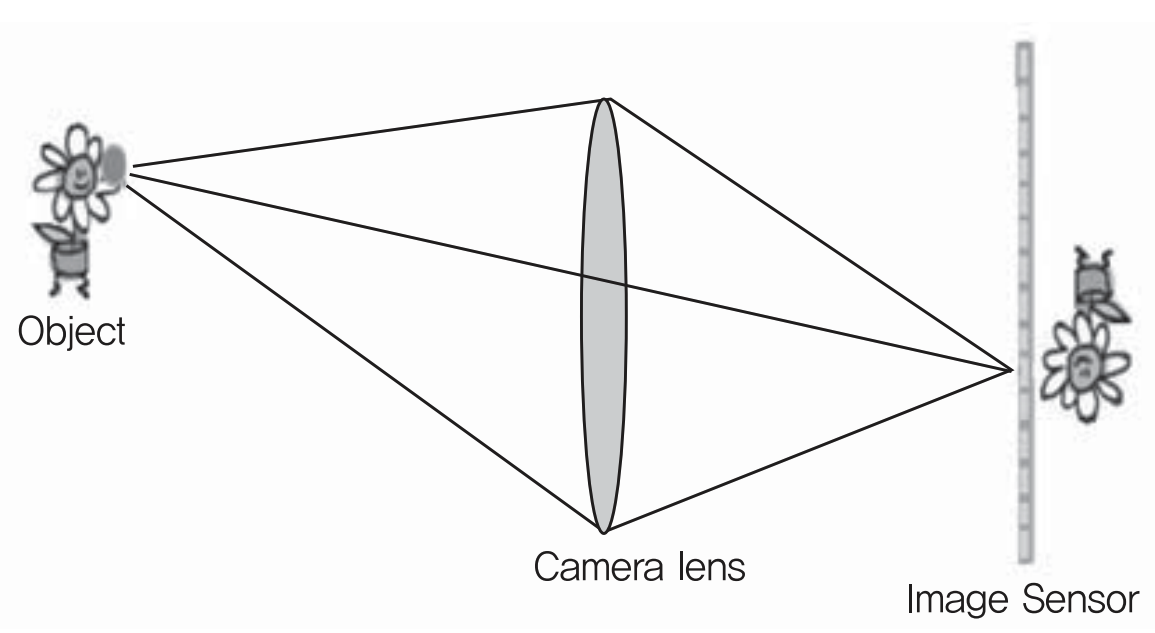
일반 2D 카메라는 렌즈를 통과한 빛이 한 점으로 모여 합쳐진 값으로 센서에 인식되기 때문에, 각 ray 가 가지고 있는 세기와 방향의 정보를 잃음
빛의 세기 정보를 표현하기 위해선 아래와 같은 plenoptic function 이 필요함
$$p=P(\theta, \phi, \lambda, V x, V y, V z, t)$$
[Gortler et al. 1996; Levoy and Hanrahan 1996] 에서 plenoptic function 을 간소화하여 4개의 매개변수 이용
이야기가 좀 새었는데, 결국 light field 를 기반으로 한 novel-view synthesis 는 마치 물체 주변을 빙글빙글 돌면서 찍은 사진들을 모아놓은 것을 통해 진행하는 것
unstructured capture 는 기존에 일정한 간격으로 사진을 찍어야했던 것과 달리, 랜덤한 방향에서 찍은 이미지로도 가능하다는 것을 뜻함
1-2 Structure-from-Motion (SfM)
[Snavely et al. 2006] 에서는 여러장의 이미지로 새로운 시점을 합성하는 기술을 고안
SfM 의 input 으로는 다른 시점에서 촬영한 여러장의 이미지가 들어감
이 이미지들의 feature 를 뽑아, 서로 다른 이미지의 동일한 point 를 추정하는 방식으로 camera calibration 정보가 output 으로 나옴
이 calibration 과정에서 point cloud 를 estimate 하여 3차원 공간을 간단하게 visualize 할 때 사용
1-3 Multi-View Stereo (MVS)
[Goesele et al. 2007] 에서는 full 3D reconstruction 을 produce 하였고 이후 여러가지 view synthesis 알고리즘에 영향을 미침
대부분의 알고리즘들은 입력을 re-project 하고 blend 하여 geometry 를 통해 re-projection 을 guide 해줌
MVS 는 SfM 의 output 인 camera pose 와 point cloud 정보를 입력으로 받아 좀 더 dense 한 결과물 제공
1-4 Neural Rendering
최근 neural net 을 기반으로 한 알고리즘들은 위 방법들의 문제를 줄이고 성능도 더 좋음
2. Neural Rendering and Radiance Fields
2-1 딥러닝의 초기 적용
딥러닝 기반의 방법들이 novel-view synthesis 에 적용되어 2016년 deepstereo paper, 2016년 appearance flow paper 등이 나왔음
CNN 을 통해 blending weight 를 estimate 하기도 함 "Deep blending for free-viewpoint image-based rendering" 2018 TOG
2-2 MVS 기반 알고리즘의 한계
대부분 MVS 를 사용한다는 단점이 존재
최종단계에서 CNN 의 사용으로 temporal flickering (프레임 간의 불안정성) 발생
2-3 부피 기반 표현
Soft3D 에서 volumetric representation 사용
하지만 volume 을 사용한 ray marching 기법은 너무 많은 sample 이 필요하기 때문에 cost 가 문제
2-4 NeRF
아는 내용이니까 넘어감
MIP-NeRF 360 이 현재까지 제일 좋은 품질을 보임
2-5 최근 방법들
Space discretization: TensoRF
Codebooks: [Takikawaet al. 2022]
Hash tables: Instant-NGP
NeRF에선 특히 빠른 학습 속도가 중요한데, Instant-NGP 와 plenoxels 모두 Spherical Harmory 를 사용하여 획기적으로 시간을 단축함
3. Point-Based Rendering and Radiance Fields
- 포인트 기반 렌더링의 기초와 발전
- 가장 단순한 형태는 고정된 크기의 포인트들을 래스터화하는 것
- 초기에는 구멍, 앨리어싱, 불연속성 등의 문제가 있었음
- 이후 "스플래팅" 기법을 통해 화질을 개선 (원형/타원형 디스크, 타원체 등 사용)
- 신경망 기반 포인트 렌더링
- 포인트에 신경망 특징을 추가하여 CNN으로 렌더링하는 방식이 등장
- 실시간 뷰 합성이 가능해졌으나, MVS(Multi-View Stereo)의 한계를 여전히 가지고 있음
- 볼륨 렌더링과의 관계
- 포인트 기반 알파 블렌딩과 NeRF 스타일의 볼륨 렌더링은 본질적으로 동일한 이미지 형성 모델을 공유
- 그러나 렌더링 알고리즘에서 차이가 있음:
- NeRF는 연속적 표현으로 랜덤 샘플링이 필요해 계산 비용이 큼
- 포인트 기반은 비구조적, 이산적 표현으로 더 유연하고 효율적
- 최신 발전 방향
- 3D 가우시안을 사용한 장면 표현 방식 도입
- 타일 기반 렌더링 알고리즘으로 실시간 렌더링 구현
- 기존 MVS 기하학에 의존하지 않으면서도 복잡한 장면을 처리할 수 있게 됨
- Method

Differentiable 3D Gaussian Splatting
- Goal
- High quality
- Differentiable volumetric representations
- Fast rendering
- Decision
- 3D Gaussians
- Reasons
- Differentiable
- Easily projected to 2D splats
일반적으로, sparse 한 SfM points 들이 주어졌을 때, 표현의 법선벡터(normals)들을 구하는 것이 어려움
► Optimization 또한 어려움
따라서 해당 논문에선 3D Gaussian 들의 집합으로 위상을 표현하여 normal 이 필요없게 하였음
아래와 같이 3D covariance matrix $Sigma$ 와 $\alpha$ 의 곱으로 gaussian 들을 표현
$$G(x)=e^{-\frac{1}{2}(x)^T \Sigma^{-1}(x)}$$
하지만 결국 필요한건 이 3D Gaussian 들을 2D 공간에 mapping 하는 것...
뷰 변환 행렬 $W$ 가 주어졌을 때, 아래와 같은 수식으로 표현 가능
(뷰 변환 행렬: World coordinate 에서 camera coordinate 으로 변환하는 4x4 행렬)
$$\Sigma^{\prime}=J W \Sigma W^T J^T$$
이때 $J$ 는 projective transformation 의 affine approximation 의 Jacobian
하지만 여기에서 문제가 하나 있는데, 이 covariance matrix $Sigma$ 를 일반적인 gradient descent 방식으로 optimize 하기가 어려움
따라서 Scaling matrix 와 rotation matrix 를 통해 $\Sigma$ 를 표현
$$\Sigma=R S S^T R^T$$
3D 벡터 s(스케일링용)와 쿼터니온 q(회전용)를 별도로 저장하고 최적화
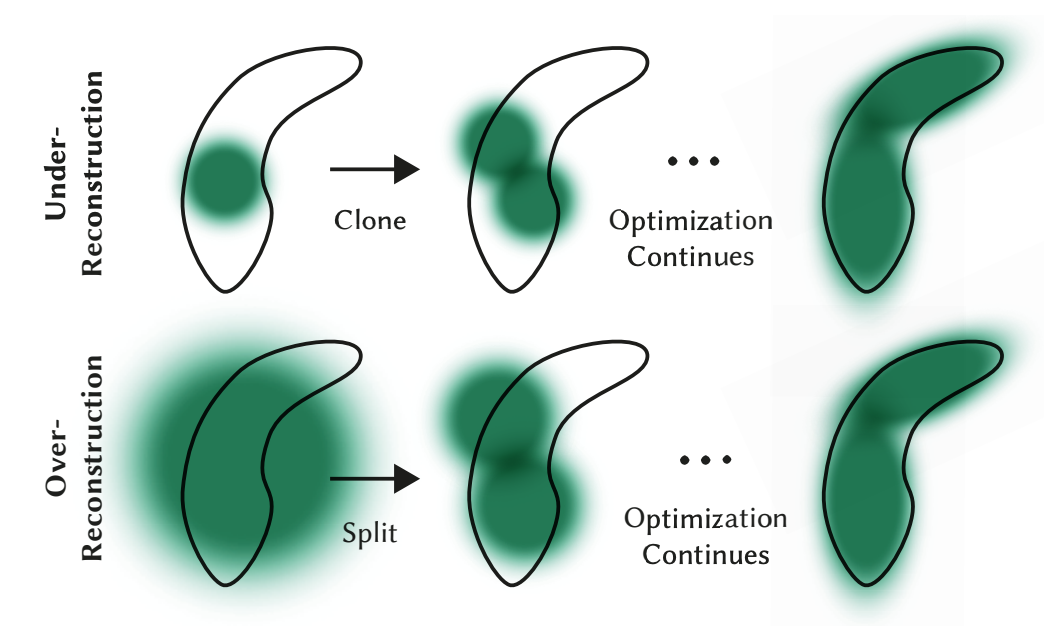
Optimization with Adaptive Density Control of 3D Gaussians
- Optimization
- 3D to 2D projection 의 모호함으로 인해 geometry 가 부정확한 경우가 발생함
- Destroy, Move 등이 필요함
- Custom CUDA kernel 을 통해 fast rasterization
- D-SSIM loss
- $\mathcal{L}=(1-\lambda) \mathcal{L}_1+\lambda \mathcal{L}_{\mathrm{D}-\mathrm{SSIM}}$
- 3D to 2D projection 의 모호함으로 인해 geometry 가 부정확한 경우가 발생함
- Adaptive Control of Gaussians
- Optimization warmup 이후, 100 iteration 마다 densify 를 진행하고, threshold 보다 낮은 $\alpha$ 값을 가지면 제거
- Under-reconsturction, Over-reconstruction 둘 다 view-space 에서 큰 position gradient 를 가짐
- Under-reconsturction
- Clone
- Position gradient 방향으로 이동
- Over-reconstruction
- Split
- 새 위치는 원본 gaussian 의 pdf 를 사용하여 샘플링
- Under-reconsturction
- Floaters
- 카메라 근처에서 발생
- 해결방법: 3000번 반복마다 $\alpha$ 값을 0에 가깝게 설정
- 불필요한 gaussian dms wprj
- Gaussian 관리: 아래와 같은 gaussian 들을 주기적으로 제거
- World space 에서 너무 큰 것
- View space 에서 footprint 가 큰 것
Fast Differentiable Rasterizer for Gaussians
- Tile-based rasterizer
- 16x16
- Fully differentiable pipeline
- Efficient memory implementation
Algorithm Pseudo Code

- 초기화 단계
- 입력으로 SfM(Structure from Motion)에서 얻은 포인트 클라우드(M)를 받습니다
- 각 가우시안에 대한 속성들을 초기화합니다:
- S: 공분산 행렬(Covariances)
- C: 색상(Colors)
- A: 불투명도(Opacities)
- 메인 최적화 루프
- 수렴할 때까지 반복:
- 학습 뷰에서 카메라 위치(V)와 해당하는 실제 이미지(Î)를 샘플링
- 현재 가우시안들을 래스터화하여 렌더링된 이미지(I) 생성
- 렌더링된 이미지와 실제 이미지 간의 손실(L) 계산
- Adam 옵티마이저를 사용하여 파라미터 업데이트
- 수렴할 때까지 반복:
- 정제(Refinement) 단계
- 특정 반복마다 다음 작업을 수행:
- 가우시안 제거(Pruning)
- 불투명도(α)가 너무 낮은 가우시안 제거
- 크기가 너무 큰 가우시안 제거
- 밀도 조정(Densification)
- 손실 그래디언트(∇pL)가 임계값(τp)보다 큰 경우:
- 만약 스케일(∥S∥)이 임계값(τS)보다 크면:
→ 가우시안을 분할(Split)
그렇지 않으면:
→ 가우시안을 복제(Clone)
- 만약 스케일(∥S∥)이 임계값(τS)보다 크면:
- 손실 그래디언트(∇pL)가 임계값(τp)보다 큰 경우:
- 가우시안 제거(Pruning)
- 특정 반복마다 다음 작업을 수행:
- Experiment
- Optimization details
- Warm-up
- 4 times smaller image resolution
- Upsample twice after 250, 500 iter
- Warm-up
- Dataset
- Test
- 13 real scenes
- Full set of scenes from Mip-NerF360
- Two scenes from Tanks&Temples
- Tow scenes from DeepBlending
- 13 real scenes
- Test
- Baseline
- Mip-Nerf360
- InstantNGP
- Plenoxels
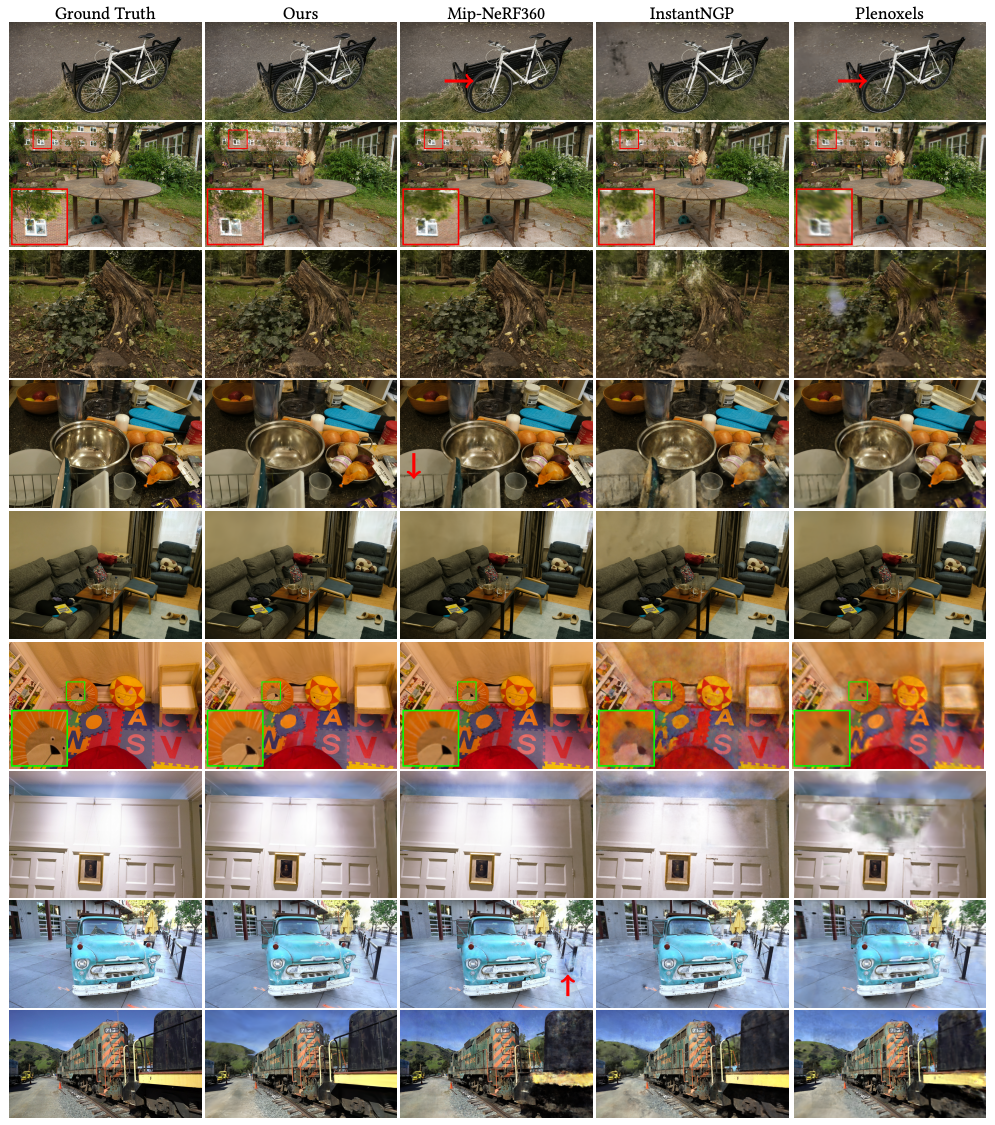


Limitations
- Artifacts
- 래스터라이저의 가드밴드를 통한 단순한 가우시안 제거
- 해결책: 더 체계적인 컬링 접근 방식 필요
- 단순한 가시성 알고리즘
- 문제: 가우시안의 깊이/블렌딩 순서가 갑자기 변경될 수 있음
- 해결책: 안티앨리어싱 적용 (향후 연구)
- 정규화 부재
- 보이지 않는 영역과 팝핑 아티팩트 개선 필요
- Reference
[1] Kerbl, Bernhard, et al. "3D Gaussian Splatting for Real-Time Radiance Field Rendering." ACM Transactions on Graphics 42.4 (2023) [Paper link]
[2] 김태원, Light Field 카메라와 기술 동향, ETRI, 2013 [Link]