- Introduction


3D aware GAN: Single view 2D 사진 collection 으로 unsupervised 3D representation 을 배우는 Generator 제안
- 3D-grounded rendering 의 computational efficiency 를 향상시킴 - 이를 통해 이전에 존재하던 resolution, quality issue 를 최소화
- Dual discrimination strategy 를 사용하여 neural rendering 과 final output 사이의 consistency 를 유지하여 바람직 하지 않은 view 의 불일치를 regularize
- 학습 중에는 pose-correlated attributes 을 잘 모델링 하면서, inference 에선 pose-based conditioning 으로 pose-correlated attributes 를 decouple
- Method


Tri-plane hybrid 3D representation
Explicit feature 를 3개의 axis-aligned orthogonal feature planes 에 align (Resolution 은 $N \times N \times C$, $N$ 은 Spatial res, $C$ 는 Channel num)
3D position $x \in \mathbb{R}^3$ 가 있을 때, 각 feature plane 에 projection 후 summation 하고 decoder 를 통과해서 density 와 color 구함
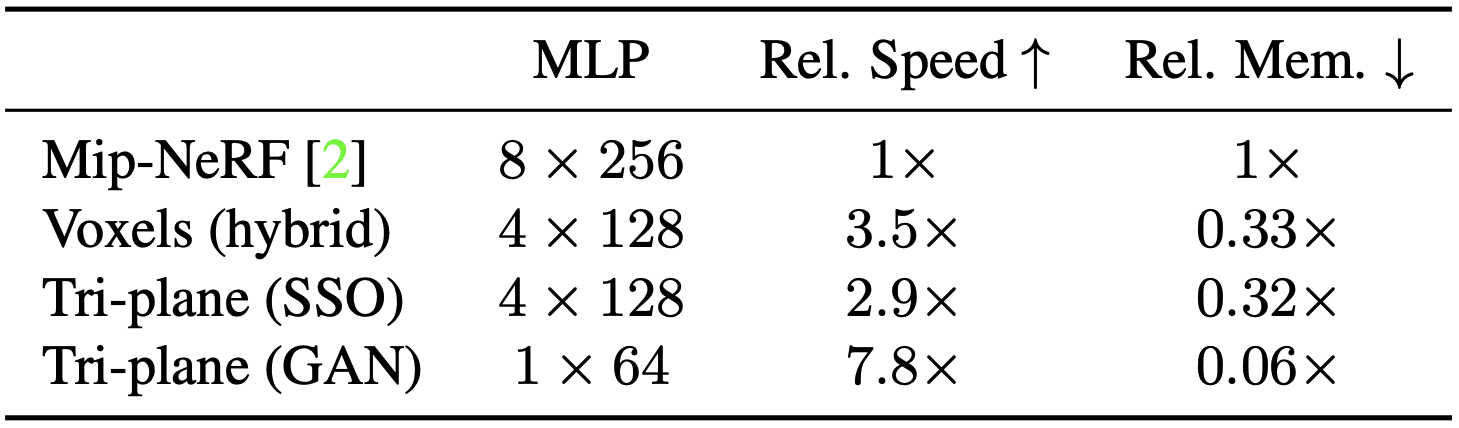
실험 결과를 보게되면 속도는 더 빠르고 메모리는 더 적게 쓰고 결과는 더 좋은 것을 보임
3D GAN framework

각 training image 를 camera intrinsic, extrinsic 과 연결한다고 함
먼저 styleGAN2 를 이용하여 $256 \times 256 \times 96$ feature map 을 구하고, 각각 32 channel 을 갖는 tri-plane 생성
여기서 바로 RGB 이미지를 구하는게 아니라, 32-channel tri-plane 으로 부터 나온 feature 를 aggregate 하여 주어진 camera pose 에 맞게 32-channel feature image 를 구함
그 다음엔 super-resolution module 을 통해 upsample 되고 마지막으로 styleGAN2 discriminator 를 통해 판단
CNN generator backbone and rendering
styleGAN2 를 수정하여 3-channel RGB image 대신 $256 \times 256 \times 96$ feature image 나오도록 하였음
이 feature image 가 channel 방향으로 split 되고 reshape 하여 3개의 32-channel plane 으로 만들고, 이를 통해 나온 aggregate feature 를 가벼운 decoder 에 통과
Decoder 는 64 unit 짜리 hidden layer 1 개를 가지는 mlp, softplus activation functions
Decoder 는 output 으로 32-channel color 와 scalar density 를 내보냄
Color 와 density 는 volume rendering 을 통해 $128 \times 128 \times 32$ feature image 로 구성
Super-resolution
2 blocks of styleGAN2 modulated conv layers for unsample
Noise input 은 사용하지 않고 mapping network 는 재사용하여 layer modulation
Dual discrimination

- Consistency between $I_{RGB}$ 와 $I_{RGB}^+$: Upsampled raw image ($512 \times 512 \times 3$) concatenated with super-resolved image ($512 \times 512 \times 3$) → Total ($512 \times 512 \times 6$)
- Neural rendering 으로 하여금 downsampling 한 실제 이미지와 분포가 match 되도록 하는 추가 효과
- Super-resolved image 가 neural rendering 에 consistent 하도록 하는 추가 효과
- Make the discriminator aware of the camera poses: camera intrinsics 와 extrinsics 를 함께 넣어줌
- Generator 가 정확한 3D prior 를 배우도록 guide
Modeling pose-correlated attributes
FFHQ 같은 현실 세계 데이터셋을 사용할 때, camera pose 와 상관관계가 있는 attribute 들이 존재
이런 상관관계가 있어야 좋은 품질의 이미지가 나오지만, multi-view synthesis 에는 이런게 오히려 악영향을 미칠 수 있음
따라서 camera pose 와 attribute 을 decouple 시켜야함 → backbone mapping network 에 camera parameter 제공
- Experiment


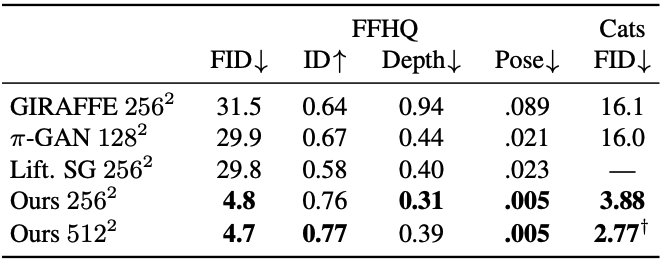
- Discussion
- Reference
[1] Chan, Eric R., et al. "Efficient geometry-aware 3D generative adversarial networks." CVPR 2022 [Paper link]