DUST3R 연구 흐름은 아래 링크 참고 바랍니다.
GitHub - Ethan-Lee-Sunghoon/Awesome-DUST3R: A curated list of awesome DUST3R/MAST3R related papers.
A curated list of awesome DUST3R/MAST3R related papers. - Ethan-Lee-Sunghoon/Awesome-DUST3R
github.com
- Introduction
현대 3D reconstruction 은 아래의 하위 분야들을 통합한 결과라고 볼 수 있음
1. Keypoint detection (키포인트 감지)
- 이미지에서 특징이 될 만한 중요한 점들을 찾아내는 과정
- 예: 모서리, 코너, 특이한 텍스처가 있는 부분 등
- 대표적인 알고리즘: SIFT, SURF, ORB 등
- 이후 3D 재구성을 위한 기준점으로 활용됨
2. Matching (매칭)
- 서로 다른 이미지에서 발견된 키포인트들 중 같은 지점을 찾아 연결하는 과정
- 예: 첫 번째 사진의 건물 모서리와 두 번째 사진의 같은 건물 모서리를 연결
- Feature descriptor를 이용해 키포인트들의 특징을 비교
- 이미지 간의 대응관계(correspondence)를 찾는 것이 목적
3. Robust estimation (견고한 추정)
- 매칭된 점들 중에서 잘못된 매칭을 제거하고 신뢰할 수 있는 매칭만 선별
- RANSAC과 같은 알고리즘 사용
- 노이즈나 이상치(outlier)에 강건한 추정을 수행
4. Structure-from-Motion (SfM)
- 2D 이미지들로부터 3D 구조와 카메라 움직임을 동시에 복원
- 카메라의 위치와 방향을 추정
- 매칭된 점들의 3D 좌표를 계산
- sparse reconstruction(드문드문한 재구성)을 생성
5. Bundle Adjustment (BA)
- SfM 결과를 최적화하는 과정
- 카메라 파라미터와 3D 점들의 위치를 동시에 미세 조정
- 재투영 오차(reprojection error)를 최소화
- 수학적으로는 대규모 비선형 최적화 문제
6. Multi-View Stereo (MVS)
- sparse reconstruction을 dense reconstruction(조밀한 재구성)으로 변환
- 3D 모델의 표면을 더 상세하게 복원
- 각 픽셀의 깊이를 추정
- 최종적으로 조밀한 점군(dense point cloud) 또는 메시(mesh) 생성
근데 이런 방식들의 치명적인 문제가 있다면, 각각의 하위 분야들은 독립적으로 이루어지며, 서로 간에 도움을 주는 게 없음
또한 전체 과정 중 초기에 좀 부실한 단계가 있다면, 결과적으로 아주 안 좋은 output 이 나옴
“an MVS algorithm is only as good as the quality of the input images and camera parameters"
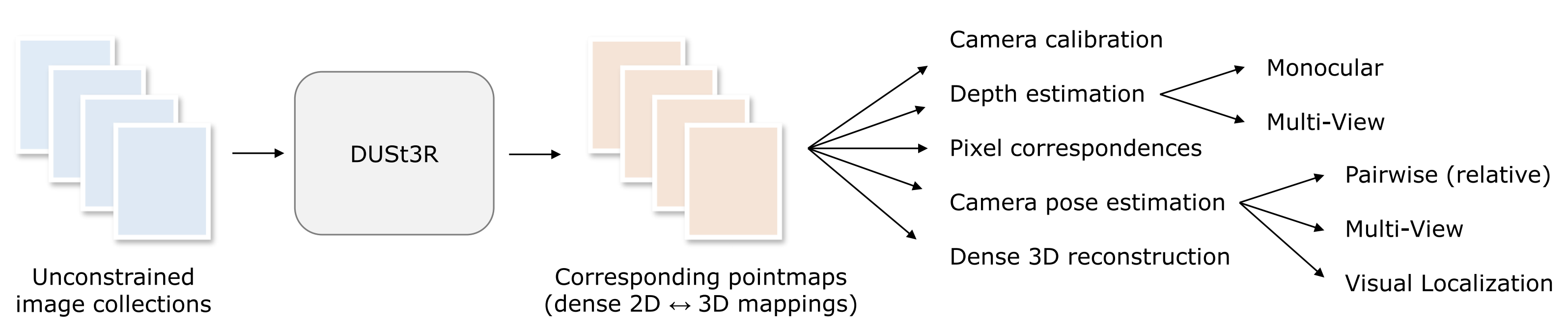
기존 MVS 분야에선 camera parameter (intrinsic, extrinsic) 가 무조건적으로 필요한데, 이걸 얻는 과정이 까다로움
해당 논문에선 제안하는 알고리즘 DUSt3R 에선 2D-3D Mapping Network 를 사용하여 이런 과정 없이 unconstrained image 로 3D reconstruction 이 가능하도록 함
*Unconstrained image: 조명 각도 거리 등이 통제되지 않은 자유로운 환경에서 촬영된 이미지
Dust3R 의 결과물로 나오는 3D pointmap 은 아래와 같은 정보를 가짐
- the scene geometry
- the relation between pixels and scene points
- the relation between the two viewpoints
Dust3R 의 Main contribution
- 혁신적인 파이프라인
- 최초의 holistic end-to-end 3D reconstruction pipeline
- un-calibrated and un-posed images 에서 작동 가능
- monocular and binocular 3D reconstruction 을 통합
- Pointmap 표현 방식 도입
- MVS applications 를 위한 새로운 representation
- canonical frame 에서의 3D shape 예측을 가능하게 함
- pixel 과 scene 사이의 implicit relationship 유지
- 새로운 optimization process
- pointmap 을 globally align 하는 optimization procedure 제안
- 기존 SfM과 MVS 파이프라인의 중간 출력들을 쉽게 추출
- 성능
- 다양한 3D 비전 작업에서 유망한 성능 달성
- monocular 및 multi-view depth 벤치마크에서 최고 수준의 결과
- Method
Pointmap
- 3D point 들로 이루어진 dense 한 2D field 인 pointmap $X \in \mathbb{R}^{W \times H \times 3}$
- $W \times H$ 의 해상도를 가지는 이미지 $I$ 에 대하여, $X$ 는 이미지 픽셀과 3차원 scene point 간의 일대일 매핑
Cameras and scene
- Camera intrinsic $K \in \mathbb{R}^{3 \times 3}$ 가 주어졌을 때, pointmap $X$ 는 depthmap $D \in \mathbb{R}^{W \times H}$ 으로 바로 구할 수 있음
- $X_{i, j}=K^{-1}\left[i D_{i, j}, j D_{i, j}, D_{i, j}\right]^{\top}$

ViT encoder, Transformer decoder, Head 로 이루어진 Siamese 형태의 network $\mathcal{F}$ 를 학습
- Input
- 2 RGB images: $I^1, I^2 \in \mathbb{R}^{W \times H \times 3}$
- Output
- Pointmaps: $X^{1,1}, X^{2,1} \in \mathbb{R}^{W \times H \times 3}$
- Confidence maps: $C^{1,1}, C^{2,1} \in \mathbb{R}^{W \times H}$
- Network architecture
- $F^1=\operatorname{Encoder}\left(I^1\right), F^2=\operatorname{Encoder}\left(I^2\right)$
- CroCo 라는 pretraining 기법? 에서 영감을 받음
- Weight sharing 진행
- $G_i^1=\operatorname{DecoderBlock}_i^1\left(G_{i-1}^1, G_{i-1}^2\right), G_i^2=\operatorname{DecoderBlock}_i^2\left(G_{i-1}^2, G_{i-1}^1\right)$
- 순차적으로 self-attention, cross-attention 진행
- $X^{1,1}, C^{1,1}=\operatorname{Head}^1\left(G_0^1, \ldots, G_B^1\right), X^{2,1}, C^{2,1}=\operatorname{Head}^2\left(G_0^2, \ldots, G_B^2\right)$
- $F^1=\operatorname{Encoder}\left(I^1\right), F^2=\operatorname{Encoder}\left(I^2\right)$
- Training objective
- 3D Regression loss
- Truth pointmaps: $\bar{X}^{1,1}$, $\bar{X}^{2,1}$
- Two corresponding sets of valid points: $\mathcal{D}^1, \mathcal{D}^2 \subseteq \{1 \ldots W\} \times\{1 \ldots H\}$
- $\ell_{\mathrm{regr}}(v, i)=\left\|\frac{1}{z} X_i^{v, 1}-\frac{1}{\bar{z}} \bar{X}_i^{v, 1}\right\|$
- Scaling factor: $z=\operatorname{norm}\left(X^{1,1}, X^{2,1}\right)$, $\bar{z}=\operatorname{norm}\left(\bar{X}^{1,1}, \bar{X}^{2,1}\right)$
- $\operatorname{norm}\left(X^1, X^2\right)=\frac{1}{\left|\mathcal{D}^1\right|+\left|\mathcal{D}^2\right|} \sum_{v \in\{1,2\}} \sum_{i \in \mathcal{D}^v}\left\|X_i^v\right\|$
- Confidence-aware loss: Real world 에선, 잘못된 3D points 가 존재할 수 있음 ► Confidence score
- $\mathcal{L}_{\mathrm{conf}}=\sum_{v \in\{1,2\}} \sum_{i \in \mathcal{D}^v} C_i^{v, 1} \ell_{\mathrm{regr}}(v, i)-\alpha \log C_i^{v, 1}$
- 항상 conf score 가 양수로 나오도록 $C_i^{v, 1}=1+\exp \widetilde{C_i^{v, 1}}>1$
- 3D Regression loss
- Downstream applications
- Point matching
- Recovering intrinsics
- Relative pose estimation
- Absolute pose estimation
- Global Alignment
- Pairwise graph
- 여러 장의 이미지를 입력으로 받아, 이미지들 간의 연결성을 그래프로 표현
- Global optimization
- 위에서 생성한 그래프를 사용하여, pointmap 정렬
- 이후 각 이미지 pair 에 대해 pointmap 예측, confidence map 계산, pose 와 scaling 조정
- Recovering camera parameters
- Camera pose
- Intrinsics
- Depthmaps
- Discussion
- Bundle adjustment 보다 해당 global optimization 이 더 빠른데, BA 에선 3D reprojection error 를 줄이는 것과 달리, 해당 논문의 optimization 기법은 3D projection error 를 줄이기 때문
- Pairwise graph
- Experiment
- Experiment details
- Train data: Indoor, outdoor, synthetic, real-world, object-centric 등을 커버
- Habitat
- MegaDepth
- ARKitScenes
- Static Scenes 3D
- Blended MVS
- ScanNet++
- CO3D-v2
- Waymo
- Training details
- Randomly select an equal number of pairs from each dataset
- 224x224 ~ 512 pixel images with randomly selected aspect ratios
- Encoder: ViT-Large
- Decoder & DPT Head: ViT-Base
- CroCo pretraining
- Evaluation
- Never finetuned on specific dataset
- Train data: Indoor, outdoor, synthetic, real-world, object-centric 등을 커버
- Visual Localization
- Datasets
- 7Scenes: 7 indoor scenes with RGB-D images and 6-DOF camera poses
- Cambridge Landmark datsets
- Results
- Datasets
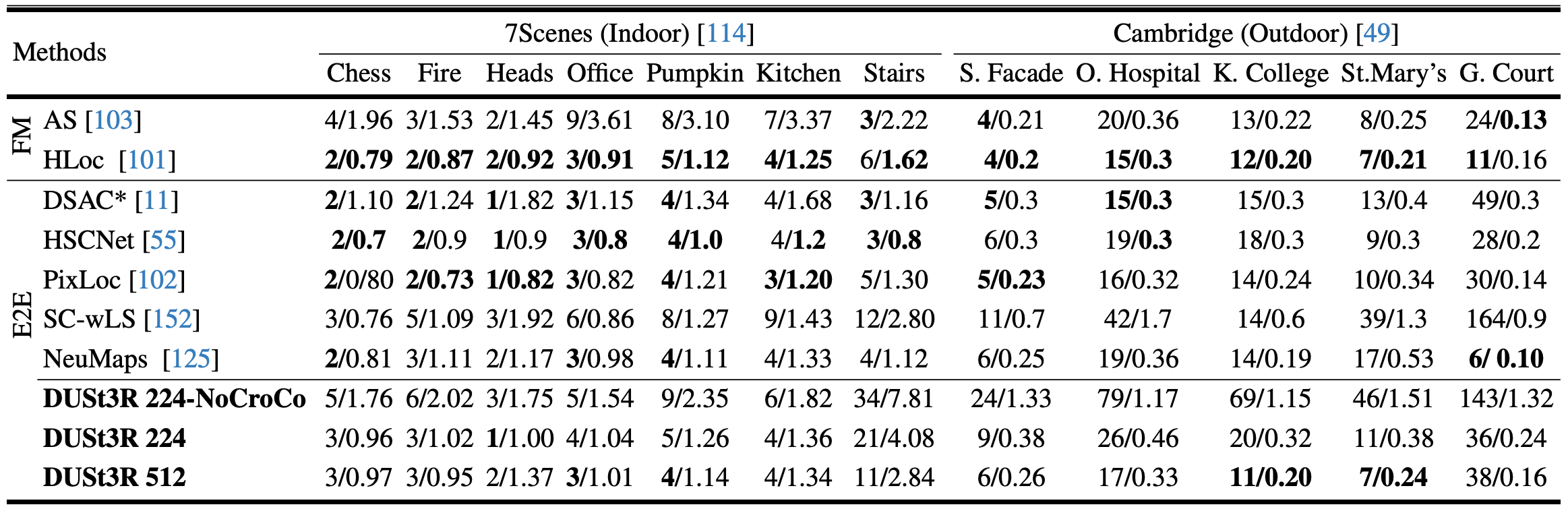
- Multi-view Pose Estimation
- Datasets
- CO3Dv2: 6 million frames extracted from 37k videos
- RealEstate10k: Indoor, outdoor dataset with 10 million frames from 80k youtube videos
- Results
- Datasets
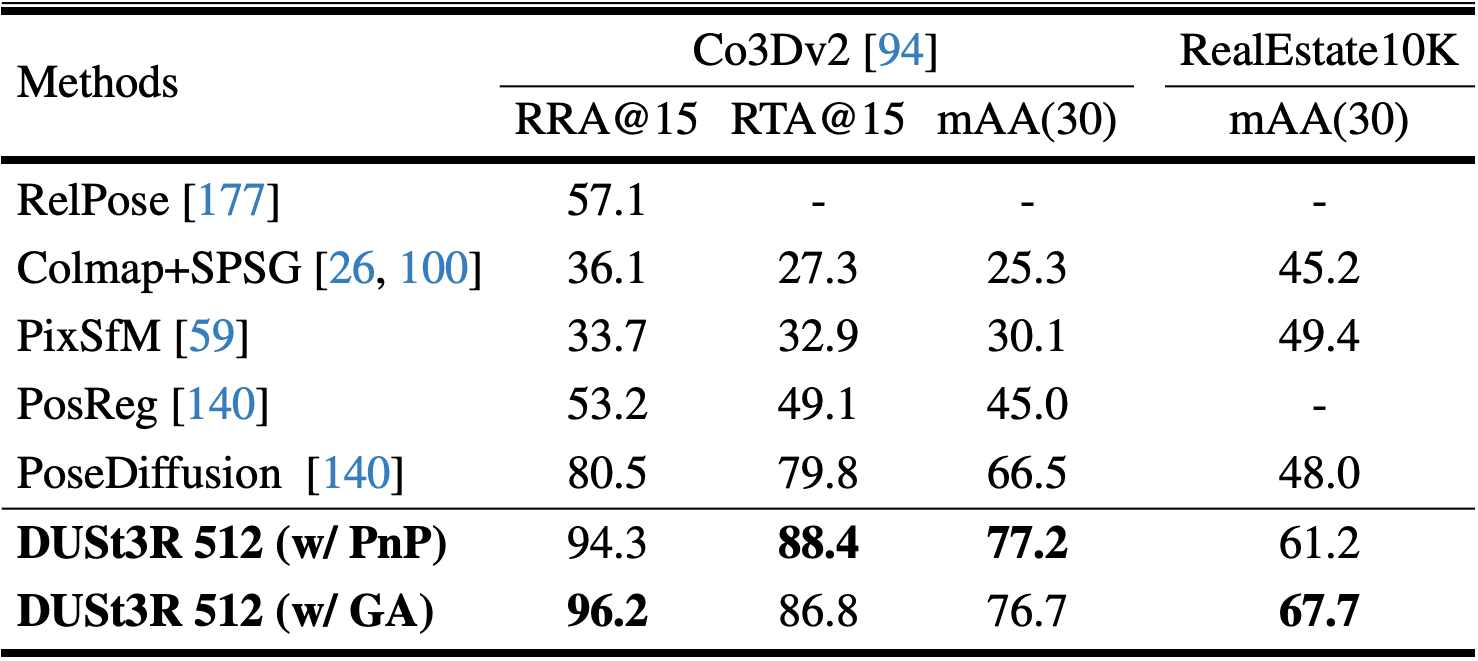
- Monocular Depth
- Datasets
- Outdoor
- DDAD
- KITTI
- Indoor
- NYUv2
- BONN
- TUM
- Outdoor
- Results
- Datasets
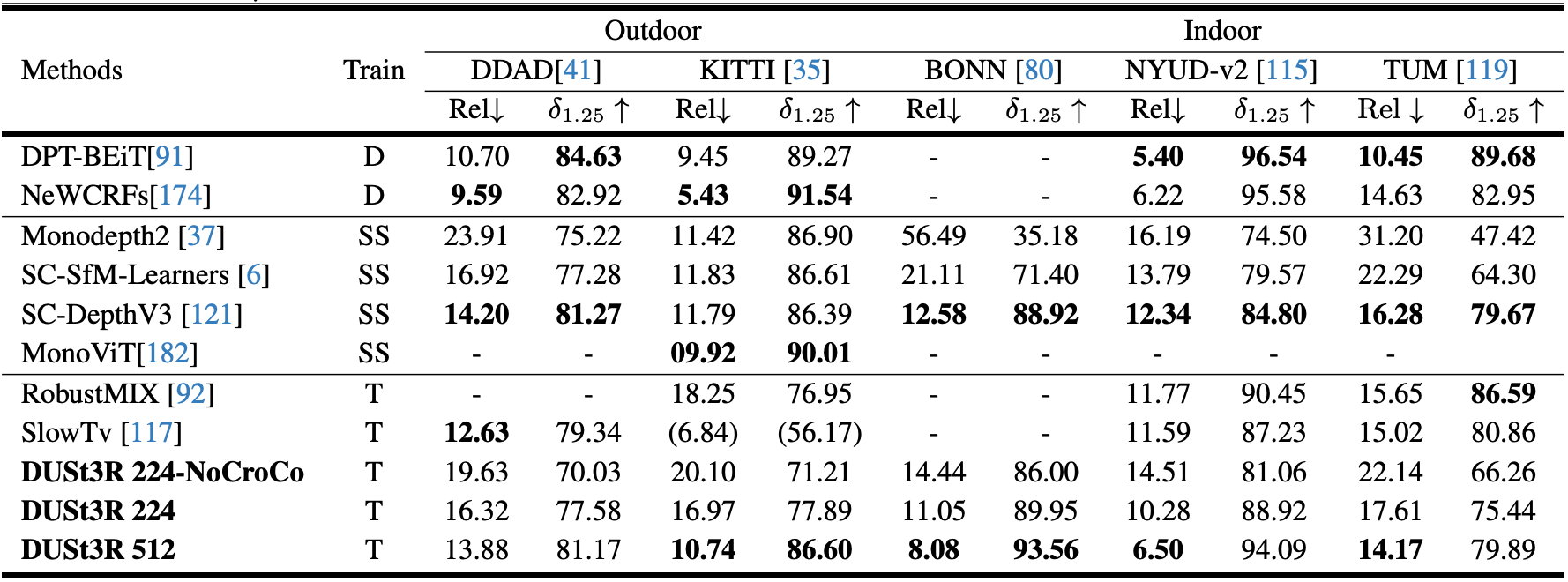
- Multi-view Depth
- Datasets
- DTU
- ETH3D
- Tanks and Temples
- ScanNet
- Results
- Datasets
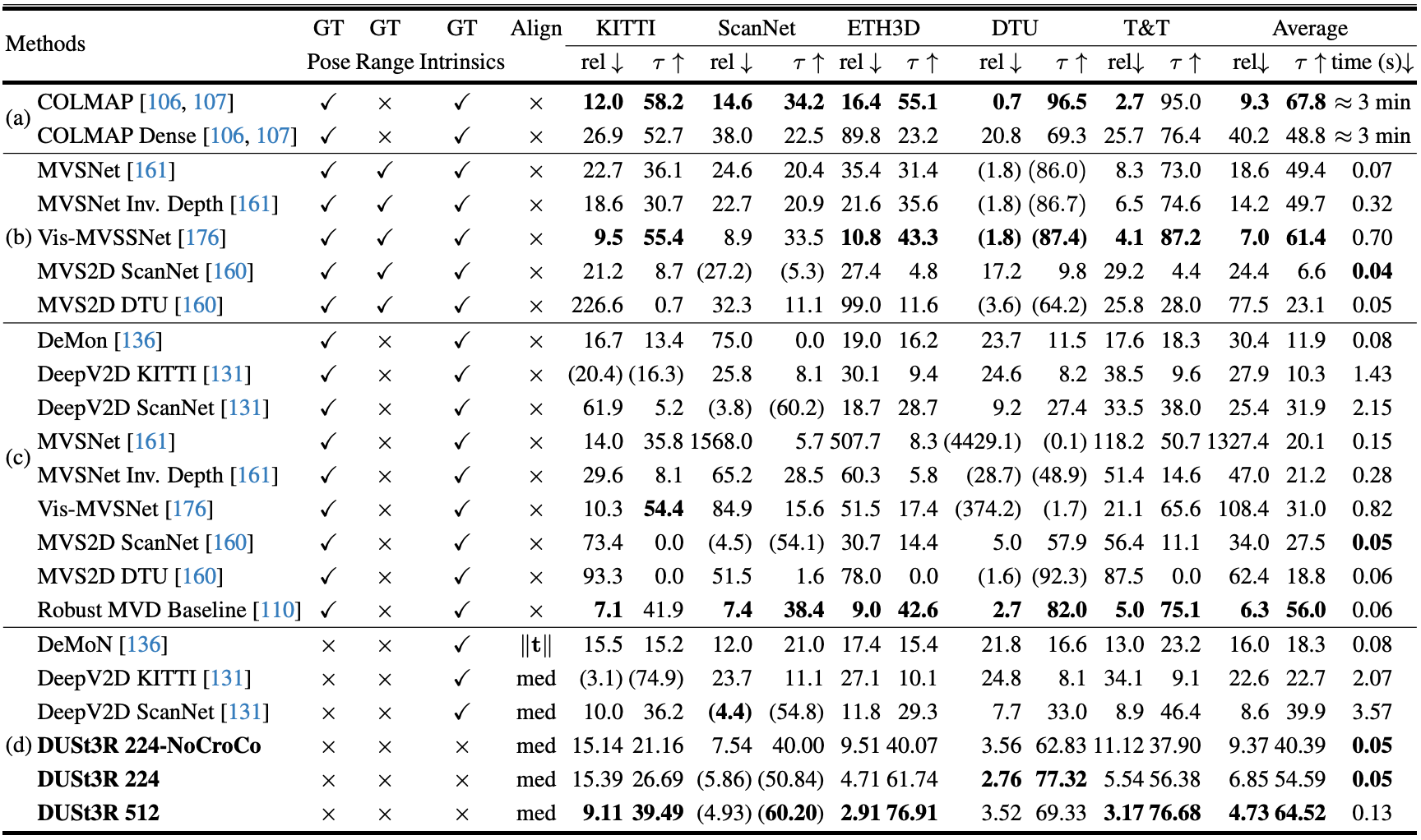
- 3D Reconstruction
- Datasets
- DTU
- Results
- Datasets
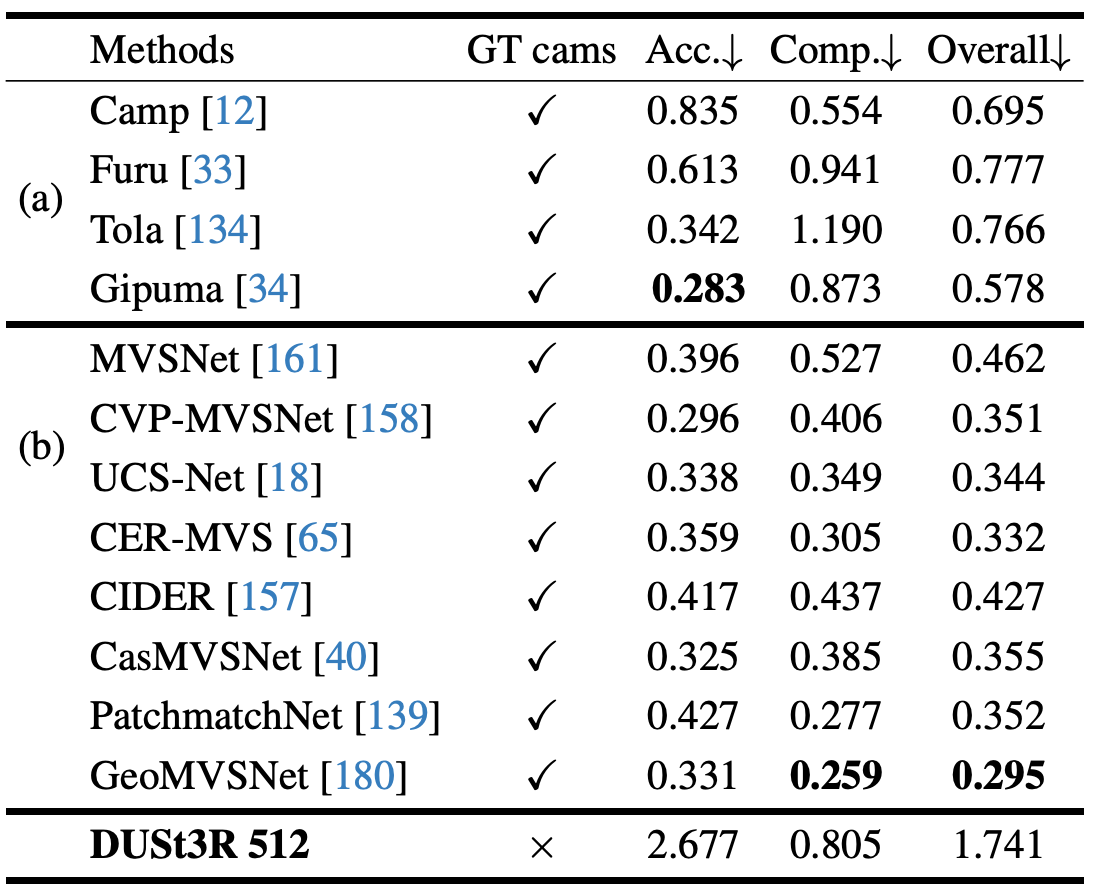


- Discussion
일단 뭐 거의 다 처음보는 내용이라 너무 어려워서 나열식으로 작성했지만, 다른 논문 읽으면서 반복적으로 나오는 내용에 대해 차차 수정을 해나가도록,,
- Reference
[1] Wang, Shuzhe, et al. "Dust3r: Geometric 3d vision made easy." CVPR 2024 [Paper link]