Variational Auto-Encoder (VAE)
: Input image $x$ 를 잘 표현하는 latent vector $z$ 로 바꾸고, 이 $z$ 를 다시 image $x$ 와 유사하지만 다른 데이터 $x^{\prime}$ 을 생성하는 Generative Model
➡︎ Auto-Encoder 라는 단어가 들어가기 때문에 관련이 있어보이지만, 구조적으로만 비슷해보일뿐, 사용 목적은 다름
Encoder
Input $x$ 가 주어졌을 때 latent $z$ 의 분포를 approximate 하는 것이 목표
즉, 평균 $\mu$ 와 표준편차 $\sigma$ 를 구하고 noise $\epsilon$ 을 추가하여 latent $z$ 를 구성
Decoder
Latent $z$ 가 주어졌을 때 $x^{\prime}$ 의 분포를 approximate 하는 것이 목표
Latent $z$ 를 output $x^{\prime}$ 으로 바꾸는 과정인데, AE 처럼 in/out 을 똑같이 사용한다면 계속 같은 이미지만 생성
따라서 $N(0,I)$ 에서 샘플링한 noise $\epsilon$ 을 추가하여 다양한 이미지를 생성할 수 있게함
$I$ 는 단위 행렬을 뜻함
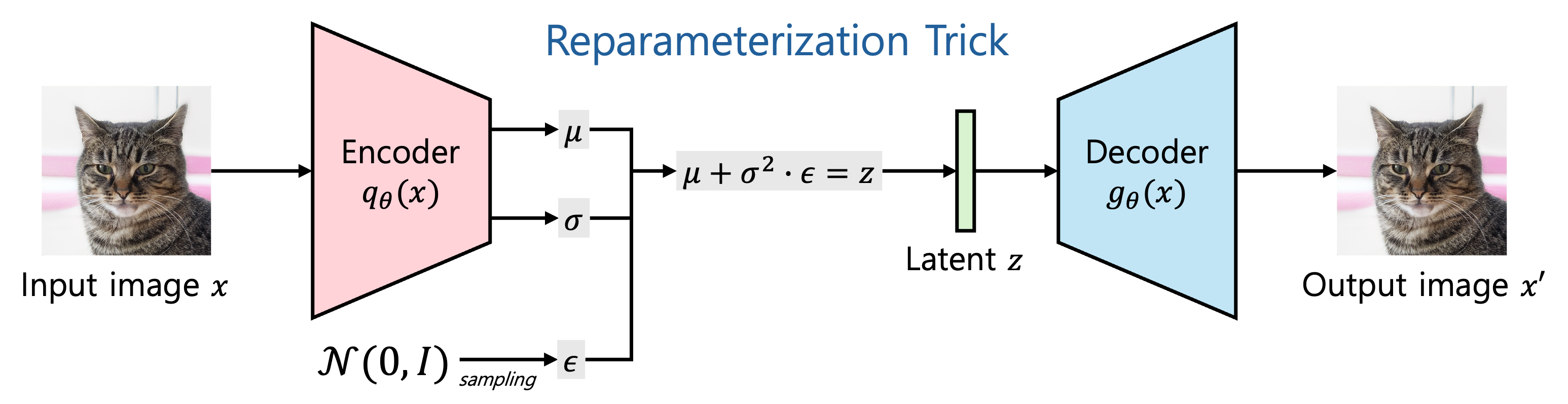
Reparameterization Trick
Latent $z$ 를 구하는 부분에서 생기는 의문은 왜 바로 $z$ 를 Normal distribution 에서 sampling 하지 않고 위와 같은 방식으로 하는가?
이유는 $N$ 에서 바로 sampling 하여 $z$ 를 구하는 경우엔 Backpropagation 이 불가능하여, 위와 같은 방식으로 우회
Loss Function
Reconstruction loss: Output 생성을 잘 할 수 있도록 하되, Decoding 된 output 이 Bernoulli 분포를 따르기 때문에 CE loss 의 형태로 구성
(Bernoulli 대신 Gaussian 으로 decoder 를 구성 가능)
Regularization: Encoding 된 값이 Normal distribution 을 따라야하기 때문에, KL divergence 로 구성
$K L\left(q_\phi(\mathbf{z} \mid \mathbf{x}) \| p(\mathbf{z})\right)$
Evidence of Lower BOund (ELBO)

$x$ 의 likelihood $p_\theta (x)$ 를 최대화해야 기존 input $x$ 와 비슷한 distribution 의 data 를 생성할 수 있음
$p_\theta(x)= \int {p_\theta(x, z) d z}= \int {p_\theta(z) p_\theta(x \mid z) d z}=\int {p_\theta(x) p_\theta(z \mid x) d z}$
${p_\theta (z)}$ 는 Gaussian 을 따른다고 가정하고 $p_\theta(x \mid z)$ 는 Decoder 에 해당하는 부분으로 Neural Net 으로 구성 가능하지만 적분이 어려워서 문제가 됨
그럼 식을 Bayes Rule 을 적용하여 $p_\theta(z \mid x)=p_\theta(x \mid z) p_\theta(z) / p_\theta(x)$ 과 같이 구성하면?
마찬가지로 $p_\theta(x \mid z)$ 는 Decoder 에 해당하는 부분, ${p_\theta (z)}$ 는 Gaussian 을 따른다고 가정하더라도 $p_\theta(x)$ 를 구할 수 없음
따라서 $p_\theta(x \mid z)$ 라는 Decoder 를 가장 잘 approximate 할 수 있는 $q_\phi(z \mid x)$ 라는 Encoder 를 만들었음
기존 likelihood 식 양변에 로그를 취하면
$\log p_\theta(x)= \int {p_\theta(z \mid x) \log p_\theta(x) d z}$
이때 위에서 말한 것처럼 Encoder 를 통하여 Approximation $p_\theta(z \mid x) \approx q_\phi(z \mid x)$ 을 적용
$\begin{aligned} \log p_\theta(\mathbf{x}) & =\int q_\phi(\mathbf{z} \mid \mathbf{x}) \log p_\theta(\mathbf{x}) d \mathbf{z} \\ & =\int q_\phi(\mathbf{z} \mid \mathbf{x}) \log \frac{p_\theta(\mathbf{x} \mid \mathbf{z}) p(\mathbf{z})}{p_\theta(\mathbf{z} \mid \mathbf{x})} d \mathbf{z} \\ & =\int q_\phi(\mathbf{z} \mid \mathbf{x}) \log \frac{p_\theta(\mathbf{x} \mid \mathbf{z}) p(\mathbf{z})}{p_\theta(\mathbf{z} \mid \mathbf{x})} \frac{q_\phi(\mathbf{z} \mid \mathbf{x})}{q_\phi(\mathbf{z} \mid \mathbf{x})} d \mathbf{z} \\ & =\int q_\phi(\mathbf{z} \mid \mathbf{x}) \log p_\theta(\mathbf{x} \mid \mathbf{z}) d \mathbf{z}-K L\left(q_\phi(\mathbf{z} \mid \mathbf{x}) \| p(\mathbf{z})\right)+K L\left(q_\phi(\mathbf{z} \mid \mathbf{x}) \| p_\theta(\mathbf{z} \mid \mathbf{x})\right) \\ & \geq \int q_\phi(\mathbf{z} \mid \mathbf{x}) \log p_\theta(\mathbf{x} \mid \mathbf{z}) d \mathbf{z}-K L\left(q_\phi(\mathbf{z} \mid \mathbf{x}) \| p(\mathbf{z})\right)\end{aligned}$
마지막 줄을 ELBO 라고 부르며, $q_\phi(\mathbf{z} \mid \mathbf{x}) \log p_\theta(\mathbf{x} \mid \mathbf{z}) d \mathbf{z}$ 는 Reconstruction loss, $K L\left(q_\phi(\mathbf{z} \mid \mathbf{x}) \| p(\mathbf{z})\right)$ 는 Regularization loss 로 보면 됨
'AI > Deep Learning' 카테고리의 다른 글
| Self Attention, Cross Attention (0) | 2024.03.11 |
|---|---|
| Autoregressive Model (0) | 2024.03.08 |
| Generative Adversarial Nets (GAN) 수식으로 이해 (0) | 2023.09.13 |
| Penultimate Layer (0) | 2023.03.17 |
| Transfer learning (0) | 2022.02.15 |