- Introduction
기존에 널리 사용하던 rehearsal based method 의 단점
- Increase memory costs
- Violate data privacy
Pretrained ViT 의 등장으로 rehearsal based method 를 대체할 prompting method 등장
일반적인 prompting method 는 key-query 메커니즘을 이용하는데, task sequence 에 end-to-end 로 학습되지 않는 문제점이 있음
이로 인해 plasticity 의 감소가 일어나고, new task의 학습이 원활하게 이루어지지 않으며, parameter capacity 증가로 이득을 얻지 못함
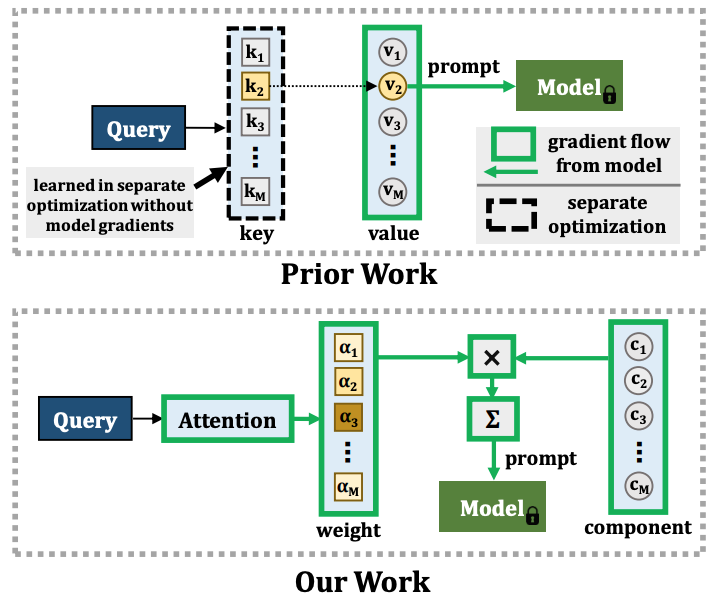
저자들은 자신들의 연구가 prior work 와 달리 end-to-end 방식으로 작동한다고 설명함
Decomposed prompt: Weighted sum of learnable prompt components, prompt pool 을 decomposed prompt 로 대체
Attention-based component-weighting scheme: End-to-end 방식으로 optimize
- Method
- Prompt Formation
Dualprompt 는 각 task 마다 single prompt 를 학습하는데 각 prompt length, 즉 capacity 를 늘려도 saturated returns
Prompts 의 learning capacity 는 task data 의 complexity 에 따라 달라져야함
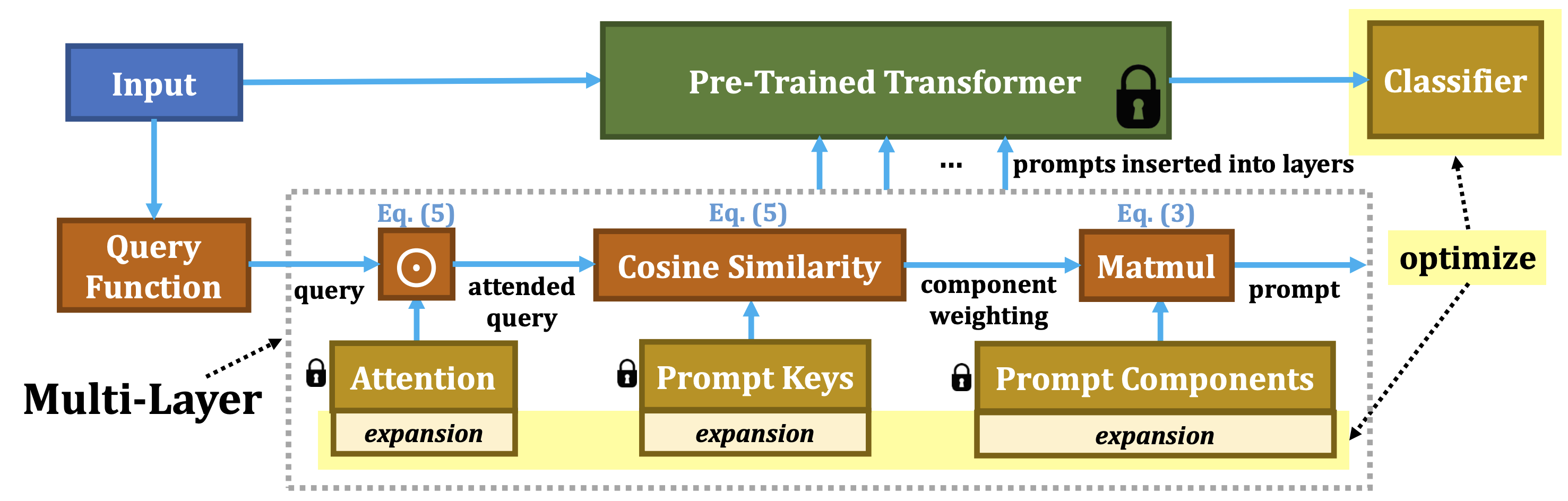
A set of prompt components: MSA 로 들어가는 decomposed prompt 제시
Prompt paramter: $\boldsymbol{p}=\sum_{m}^{}\alpha _m\textbf{P}_\textbf{m}$, weighted sum over prompt components
Set of prompt components: $\textbf{P}_\textbf{m}\in \mathbb{R}^{L_p \times D\times M}$, M is the length of the set
L2P, Dualprompt 와 다른점: L2P, DP 에서는 key 의 학습이 classification loss 로 한 번에 되지 않고 seperated optimization 과정을 가진 반면, CODA-prompt 는 end-to-end 로 학습
- Prompt-Component Weighting
Weight vector: $\alpha=\gamma (q(x),\textbf{K})=\left\{ \gamma (q(x),\textbf{K}_1),...,\gamma (q(x),\textbf{K}_M)\right\}$
Keys: $\textbf{K}_\textbf{m}\in \mathbb{R}^{D\times M}$
Prompt-query matching 은 고차원의 space D 에서 clustering 을 진행하는 well-known difficult problem 으로 생각할 수 있음
이 문제를 해결하기 위해 또다른 component 를 제시
Attention: $\textbf{A}_m\in \mathbb{R}^{D\times M}$, learnable parameters
Weight vector with attended query: $\alpha=\gamma (q(x)\odot \textbf{A},\textbf{K})=\left\{ \gamma (q(x)\odot \textbf{A}_1,\textbf{K}_1),...,\gamma (q(x)\odot \textbf{A}_M,\textbf{K}_M)\right\}$
- Expansion & Orthogonality
전체 M 개의 parameter component 와 N 개의 task
각 task 마다 $\frac{M}{N}$ 개의 parameter 만 업데이트됨, 다른 task 의 parameter 는 fixed 되어 forgetting 을 방지
기존 task 와 interference 가 일어날 수 있기 때문에, 각각을 orthogonal 하게 해주는 loss 를 추가
Orthogonality penalty loss: $\boldsymbol{L}_{ortho}(B)=\left\| BB^\top -I\right\|_2$
- Experiment
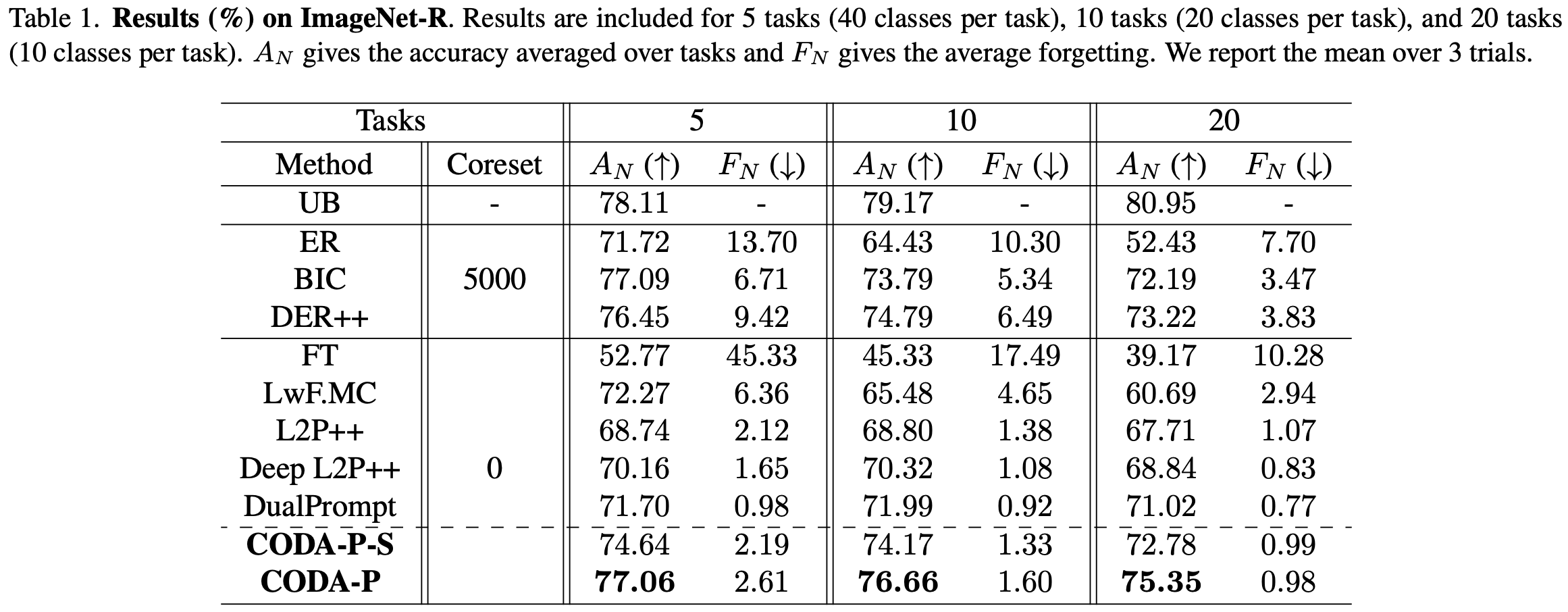
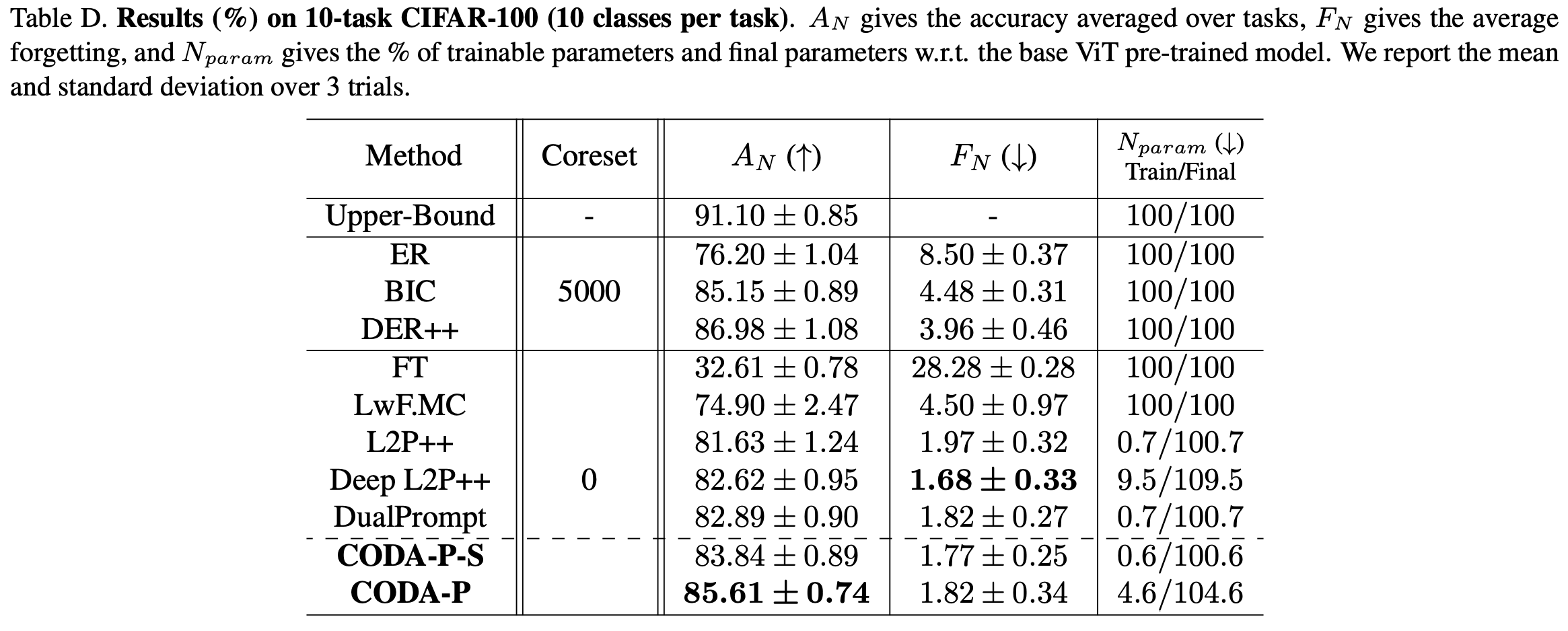
- Discussion
기존 L2P, DualPrompt 에서 Problem definition 을 새롭게 하였음
Instancewise prompt
- Reference
[1] Smith, James Seale, et al. "CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning." CVPR 2023 [Paper link]