- Introduction
OOD detection 의 main challenge
- Deep neural network 가 OOD sample 에 대해서 overconfident 한 prediction 을 보임
- ID (In-Distribution) 과 OOD 의 구분을 어렵게 만듦
- 기존 OOD 기법들은 sparcification 을 간과하며 오직 overparameterized weight 만을 이용하여 OOD score 를 계산

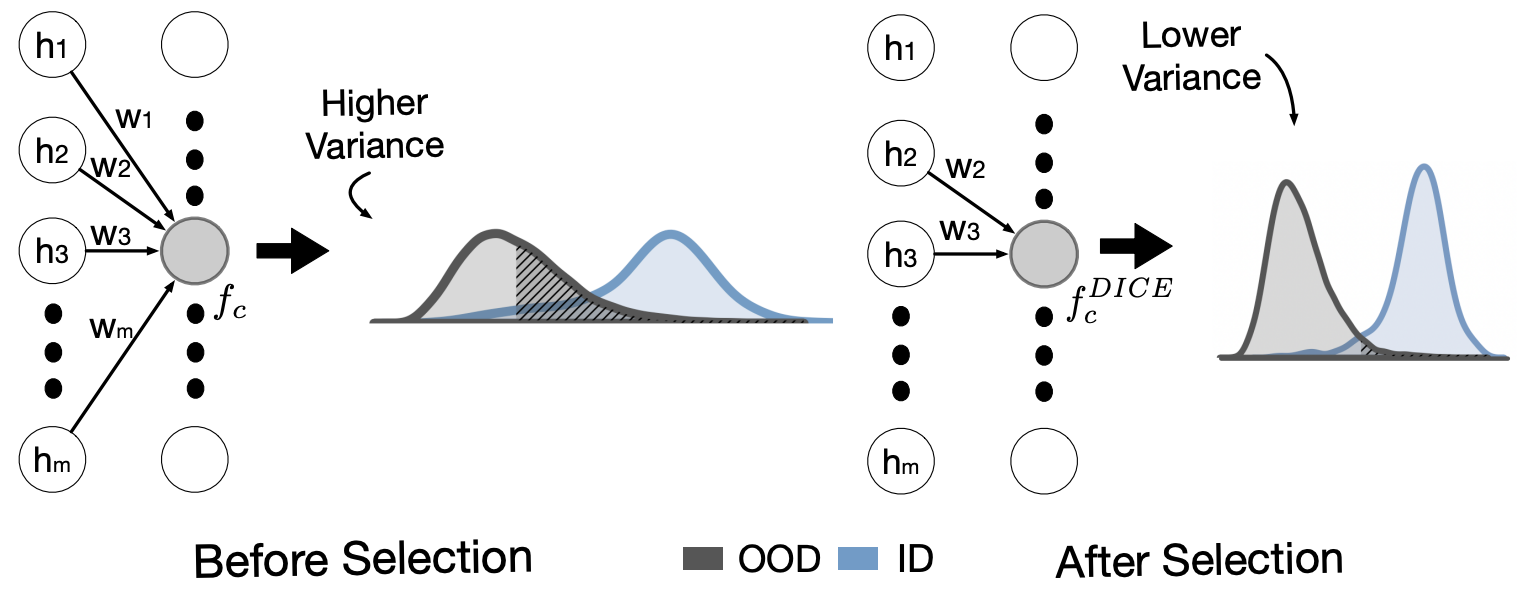
저자들은 중요하지 않은 unit 과 weight 에 의존하는것이 OOD detection 을 취약하게 만들 수 있다고 주장
ID 인 CIFAR10 에 학습된 network 가 OOD 인 SVHN 의 데이터가 입력으로 들어왔을 때 무시할 수 없을 정도의 unit 을 penultimate layer 에서 활성화 시킴
► Directed Sparcification (DICE): ID class 에 대한 prediction 은 중요한 unit 의 일부에게만 의존
- Method
Classic classification: 마지막 layer 에서 나온 feature 에 weight 를 곱한 후 softmax 를 취하여 prediction
DICE: 모든 unit 과 weight 을 사용하면 suboptimal prediction 의 가능성이 존재하기 때문에, sparcification 을 이용하여 일부 unit 과 weight 만을 select 하여 lower variance prediction 을 진행
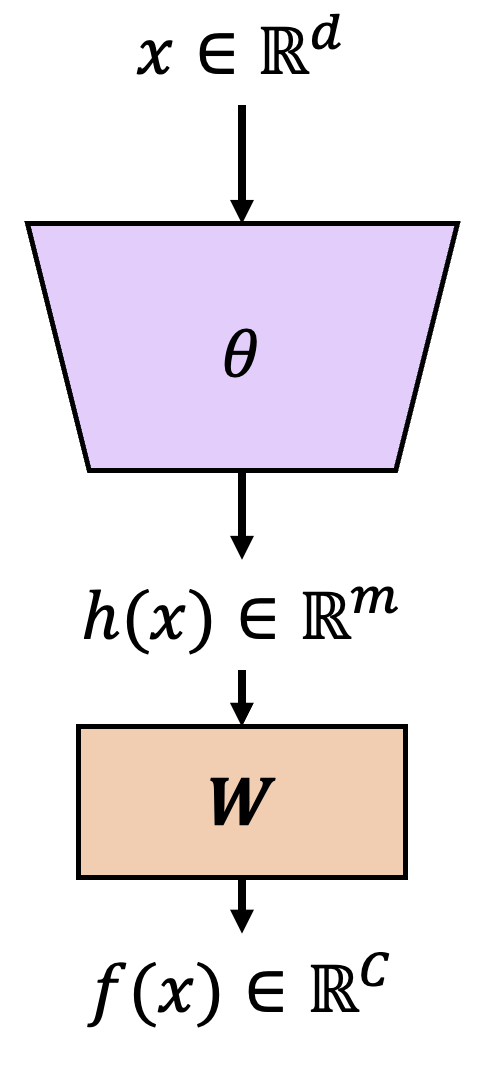
Neural network: $\theta$
Input: $\mathbf{x}\in \mathbb{R}^{d}$
Feature vector from the penulimate layer: $h(\mathbf{x})\in \mathbb{R}^{m}$
Classifier weight: $\textbf{W}\in\mathbb{R}^{m\times C}$; $h(\mathbf{x})$ to $f(\textbf{x})$
Contribution matrix: $\textbf{V}\in \mathbb{R}^{m\times C}$, Directed sparcification is based on the measure of contribution
Each column for contribution matrix: $\textbf{v}_c=\mathbb{E}[\textbf{w}_c\odot h(x)]$, 기존 classifier weight 에 logit 값 곱한 vector
Contribution-directed sparcification: $f^{DICE}(x,\theta )=(\textbf{M}\odot \textbf{W})^\top h(x)+b$
Sparsity parameter p: $p=1-\frac{k}{m\cdot C}$, 기존 matrix $\textbf{W}$ 에서 몇 % 만큼 weight drop 할지 정하는 p
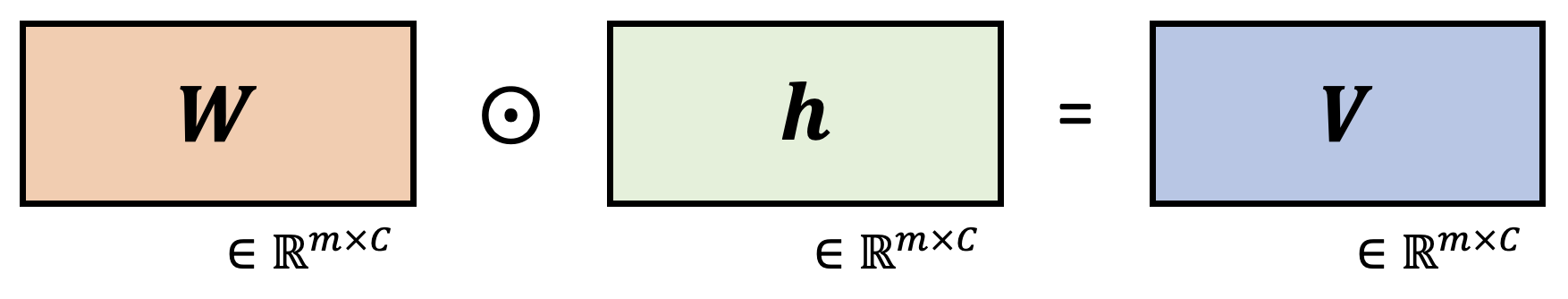
OOD Detection with DICE: $g_\lambda (x)=\begin{Bmatrix}
in & S_\theta \geq \lambda \\
out & S_\theta < \lambda \\
\end{Bmatrix}$
Scoring function: Based on energy function, $S_\theta (x)=-E_\theta (x)=log\sum_{c=1}^{C}exp\left ( f^{DICE}(x,\theta)\right )$ (High score means ID, low score means OOD)
- Experiment
Datasets: CIFAR-10, CIFAR-100 for ID data / Textures, SVHN, Places365, LSUN-Crop, LSUN-Resize, iSUN for OOD data
Backbone: DenseNet-101


- Discussion
요약
- Train 된 fixed 모델에 input image 를 넣어서 마지막 전 layer 에서 logit 값 h(x) 구함
- h(x) 를 기존 classifier weight에 곱한 후, 높은 weight 값을 가지는 top-k 를 제외한 나머지는 0 으로 masking
- Masking 된 weight 에 h(x) 를 통과시켜 softmax 분모와 비슷하게 생긴 scoring metric 으로 OOD scoring
- 낮은 score 를 가질수록 OOD data, 높은 score 를 가질수록 ID data
- Reference
[1] Sun, Yiyou, and Yixuan Li. "Dice: Leveraging sparsification for out-of-distribution detection." ECCV 2022 [Paper link]